 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR-ConstraintBench: Evaluating LLMs on NP-Complete Scheduling
Aug 21, 2025Effective scheduling under tight resource, timing, and operational constraints underpins large-scale planning across sectors such as capital projects, manufacturing, logistics, and IT fleet transitions. However, the reliability of large language models (LLMs) when reasoning under high-constraint regimes is insufficiently characterized. To address this gap, we present R-ConstraintBench, a scalable framework that evaluates models on Resource-Constrained Project Scheduling Problems (RCPSP), an NP-Complete feasibility class, while difficulty increases via linear growth in constraints. R-ConstraintBench incrementally increases non-redundant precedence constraints in Directed Acyclic Graphs (DAGs) and then introduces downtime, temporal windows, and disjunctive constraints. As an illustrative example, we instantiate the benchmark in a data center migration setting and evaluate multiple LLMs using feasibility and error analysis, identifying degradation thresholds and constraint types most associated with failure. Empirically, strong models are near-ceiling on precedence-only DAGs, but feasibility performance collapses when downtime, temporal windows, and disjunctive constraints interact, implicating constraint interaction, not graph depth, as the principal bottleneck. Performance on clean synthetic ramps also does not guarantee transfer to domain-grounded scenarios, underscoring limited generalization.
LEMDA: A Novel Feature Engineering Method for Intrusion Detection in IoT Systems
Apr 20, 2024



Intrusion detection systems (IDS) for the Internet of Things (IoT) systems can use AI-based models to ensure secure communications. IoT systems tend to have many connected devices producing massive amounts of data with high dimensionality, which requires complex models. Complex models have notorious problems such as overfitting, low interpretability, and high computational complexity. Adding model complexity penalty (i.e., regularization) can ease overfitting, but it barely helps interpretability and computational efficiency. Feature engineering can solve these issues; hence, it has become critical for IDS in large-scale IoT systems to reduce the size and dimensionality of data, resulting in less complex models with excellent performance, smaller data storage, and fast detection. This paper proposes a new feature engineering method called LEMDA (Light feature Engineering based on the Mean Decrease in Accuracy). LEMDA applies exponential decay and an optional sensitivity factor to select and create the most informative features. The proposed method has been evaluated and compared to other feature engineering methods using three IoT datasets and four AI/ML models. The results show that LEMDA improves the F1 score performance of all the IDS models by an average of 34% and reduces the average training and detection times in most cases.
TRUST XAI: Model-Agnostic Explanations for AI With a Case Study on IIoT Security
May 02, 2022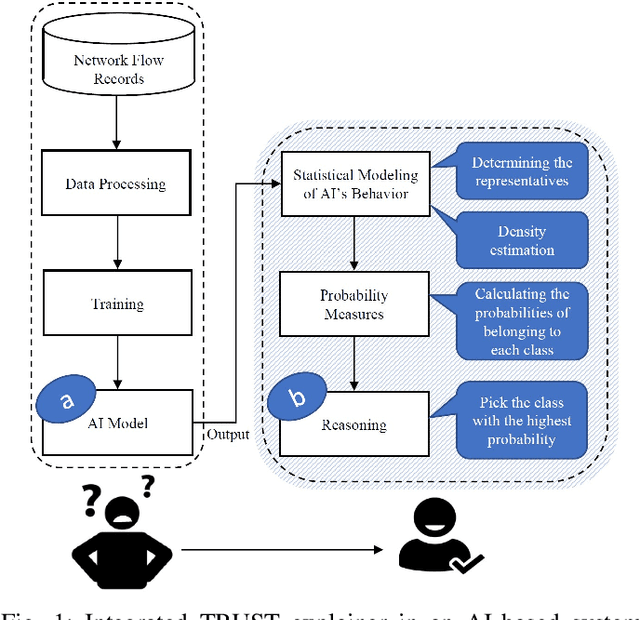



Despite AI's significant growth, its "black box" nature creates challenges in generating adequate trust. Thus, it is seldom utilized as a standalone unit in IoT high-risk applications, such as critical industrial infrastructures, medical systems, and financial applications, etc. Explainable AI (XAI) has emerged to help with this problem. However, designing appropriately fast and accurate XAI is still challenging, especially in numerical applications. Here, we propose a universal XAI model named Transparency Relying Upon Statistical Theory (TRUST), which is model-agnostic, high-performing, and suitable for numerical applications. Simply put, TRUST XAI models the statistical behavior of the AI's outputs in an AI-based system. Factor analysis is used to transform the input features into a new set of latent variables. We use mutual information to rank these variables and pick only the most influential ones on the AI's outputs and call them "representatives" of the classes. Then we use multi-modal Gaussian distributions to determine the likelihood of any new sample belonging to each class. We demonstrate the effectiveness of TRUST in a case study on cybersecurity of the industrial Internet of things (IIoT) using three different cybersecurity datasets. As IIoT is a prominent application that deals with numerical data. The results show that TRUST XAI provides explanations for new random samples with an average success rate of 98%. Compared with LIME, a popular XAI model, TRUST is shown to be superior in the context of performance, speed, and the method of explainability. In the end, we also show how TRUST is explained to the user.
ADDAI: Anomaly Detection using Distributed AI
May 02, 2022

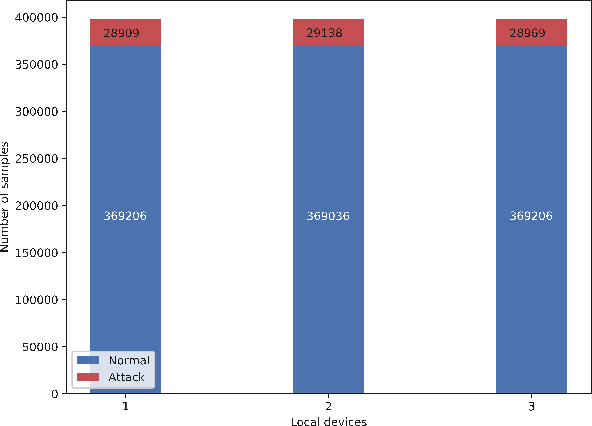

When dealing with the Internet of Things (IoT), especially industrial IoT (IIoT), two manifest challenges leap to mind. First is the massive amount of data streaming to and from IoT devices, and second is the fast pace at which these systems must operate. Distributed computing in the form of edge/cloud structure is a popular technique to overcome these two challenges. In this paper, we propose ADDAI (Anomaly Detection using Distributed AI) that can easily span out geographically to cover a large number of IoT sources. Due to its distributed nature, it guarantees critical IIoT requirements such as high speed, robustness against a single point of failure, low communication overhead, privacy, and scalability. Through empirical proof, we show the communication cost is minimized, and the performance improves significantly while maintaining the privacy of raw data at the local layer. ADDAI provides predictions for new random samples with an average success rate of 98.4% while reducing the communication overhead by half compared with the traditional technique of offloading all the raw sensor data to the cloud.
Effect of Imbalanced Datasets on Security of Industrial IoT Using Machine Learning
Dec 02, 2019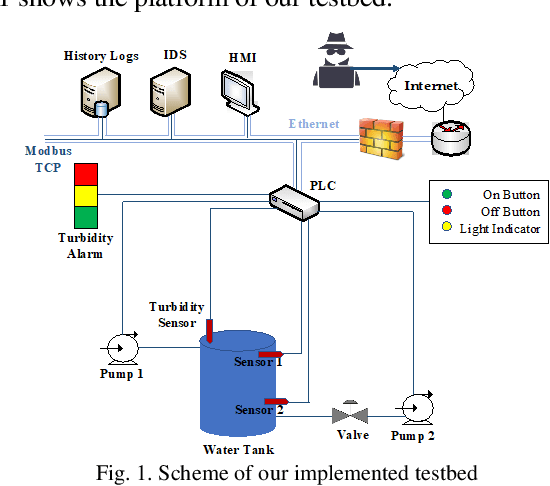
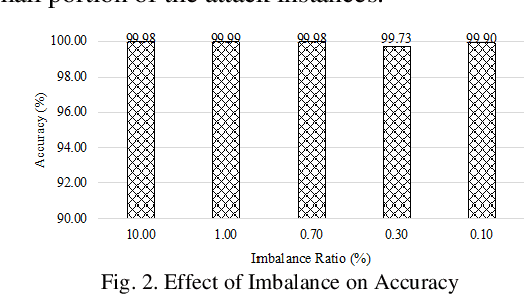
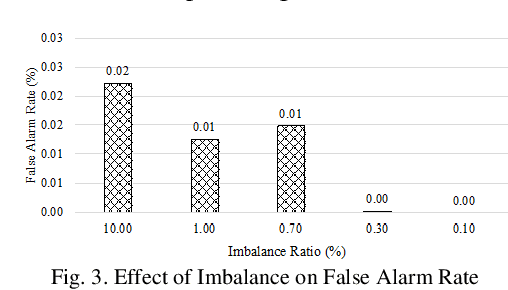
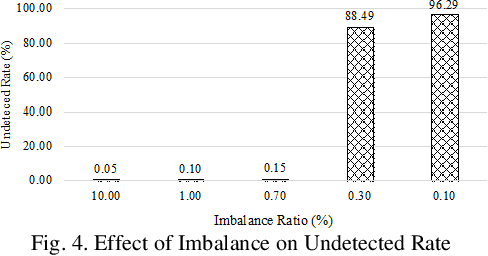
Machine learning algorithms have been shown to be suitable for securing platforms for IT systems. However, due to the fundamental differences between the industrial internet of things (IIoT) and regular IT networks, a special performance review needs to be considered. The vulnerabilities and security requirements of IIoT systems demand different considerations. In this paper, we study the reasons why machine learning must be integrated into the security mechanisms of the IIoT, and where it currently falls short in having a satisfactory performance. The challenges and real-world considerations associated with this matter are studied in our experimental design. We use an IIoT testbed resembling a real industrial plant to show our proof of concept.
Machine Learning Based Network Vulnerability Analysis of Industrial Internet of Things
Nov 13, 2019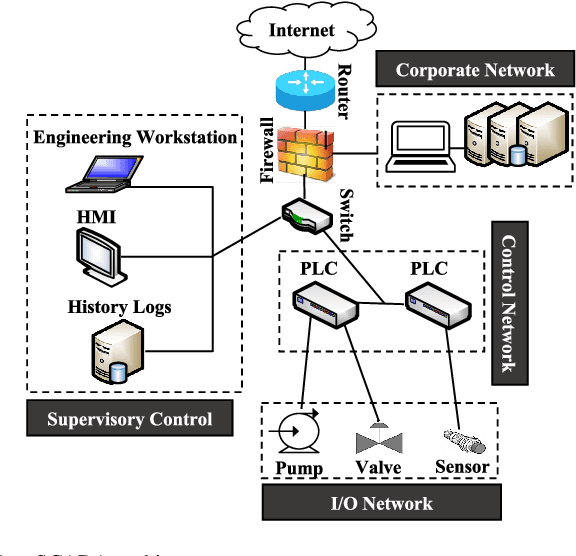
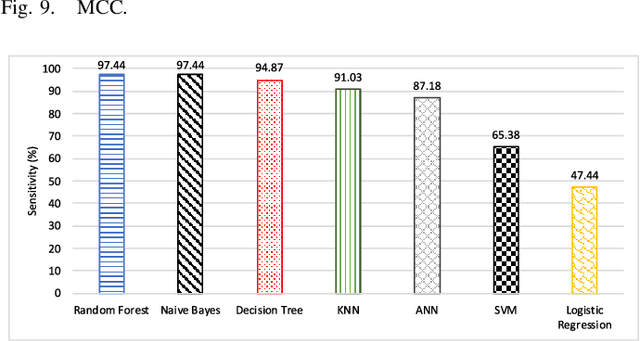
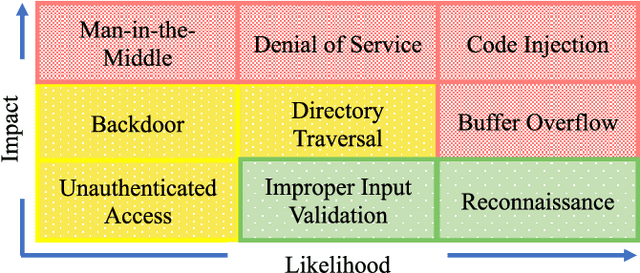
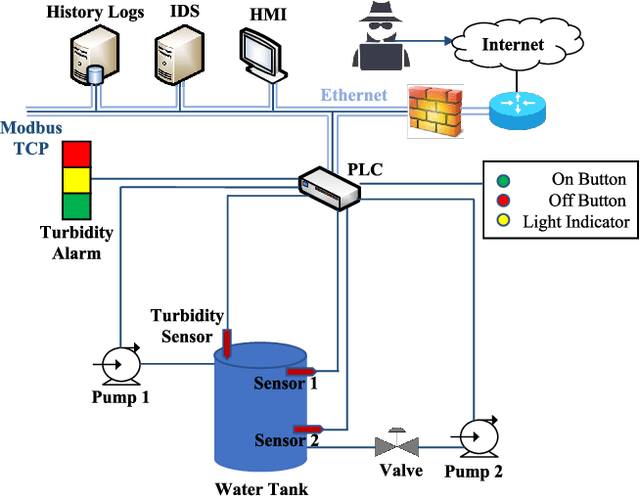
It is critical to secure the Industrial Internet of Things (IIoT) devices because of potentially devastating consequences in case of an attack. Machine learning and big data analytics are the two powerful leverages for analyzing and securing the Internet of Things (IoT) technology. By extension, these techniques can help improve the security of the IIoT systems as well. In this paper, we first present common IIoT protocols and their associated vulnerabilities. Then, we run a cyber-vulnerability assessment and discuss the utilization of machine learning in countering these susceptibilities. Following that, a literature review of the available intrusion detection solutions using machine learning models is presented. Finally, we discuss our case study, which includes details of a real-world testbed that we have built to conduct cyber-attacks and to design an intrusion detection system (IDS). We deploy backdoor, command injection, and Structured Query Language (SQL) injection attacks against the system and demonstrate how a machine learning based anomaly detection system can perform well in detecting these attacks. We have evaluated the performance through representative metrics to have a fair point of view on the effectiveness of the methods.
Feasibility of Supervised Machine Learning for Cloud Security
Oct 23, 2018



Cloud computing is gaining significant attention, however, security is the biggest hurdle in its wide acceptance. Users of cloud services are under constant fear of data loss, security threats and availability issues. Recently, learning-based methods for security applications are gaining popularity in the literature with the advents in machine learning techniques. However, the major challenge in these methods is obtaining real-time and unbiased datasets. Many datasets are internal and cannot be shared due to privacy issues or may lack certain statistical characteristics. As a result of this, researchers prefer to generate datasets for training and testing purpose in the simulated or closed experimental environments which may lack comprehensiveness. Machine learning models trained with such a single dataset generally result in a semantic gap between results and their application. There is a dearth of research work which demonstrates the effectiveness of these models across multiple datasets obtained in different environments. We argue that it is necessary to test the robustness of the machine learning models, especially in diversified operating conditions, which are prevalent in cloud scenarios. In this work, we use the UNSW dataset to train the supervised machine learning models. We then test these models with ISOT dataset. We present our results and argue that more research in the field of machine learning is still required for its applicability to the cloud security.