 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic cyber risk estimation with Competitive Quantile Autoregression
Jan 25, 2021
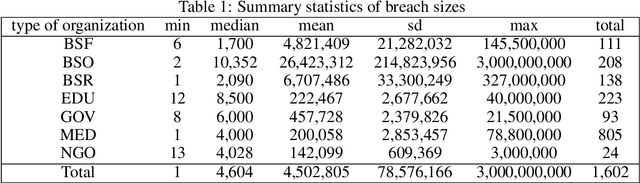
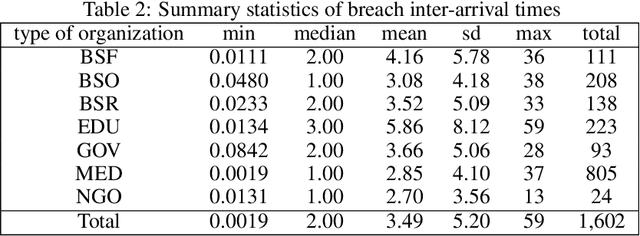
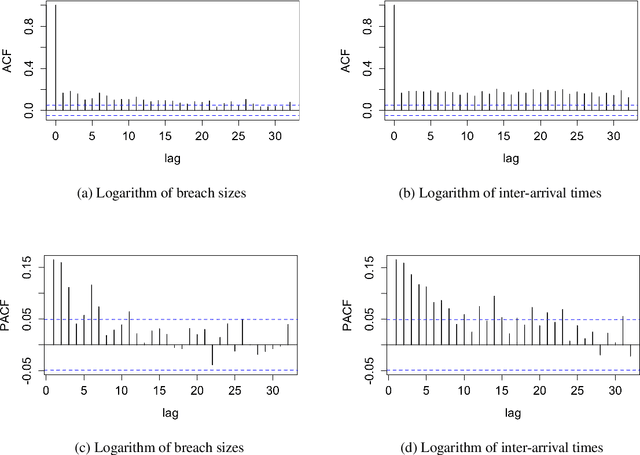
Cyber risk estimation is an essential part of any information technology system's design and governance since the cost of the system compromise could be catastrophic. An effective risk framework has the potential to predict, assess, and mitigate possible adverse events. We propose two methods for modelling Value-at-Risk (VaR) which can be used for any time-series data. The first approach is based on Quantile Autoregression (QAR), which can estimate VaR for different quantiles, i.e. confidence levels. The second method, called Competitive Quantile Autoregression (CQAR), dynamically re-estimates cyber risk as soon as new data becomes available. This method provides a theoretical guarantee that it asymptotically performs as well as any QAR at any time point in the future. We show that these methods can predict the size and inter-arrival time of cyber hacking breaches by running coverage tests. The proposed approaches allow to model a separate stochastic process for each significance level and therefore provide more flexibility compared to previously proposed techniques. We provide a fully reproducible code used for conducting the experiments.
Real-time anomaly detection with superexperts
Oct 08, 2020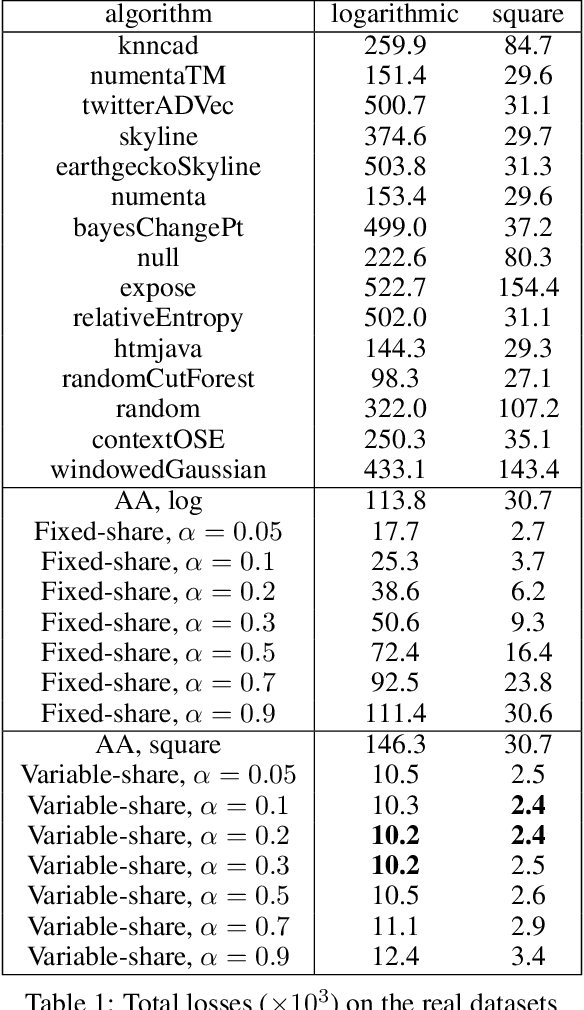
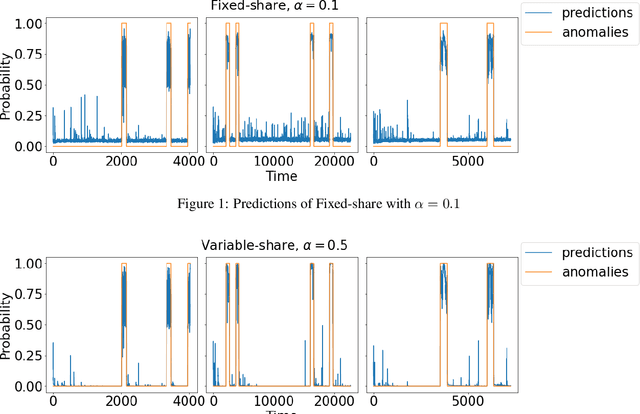
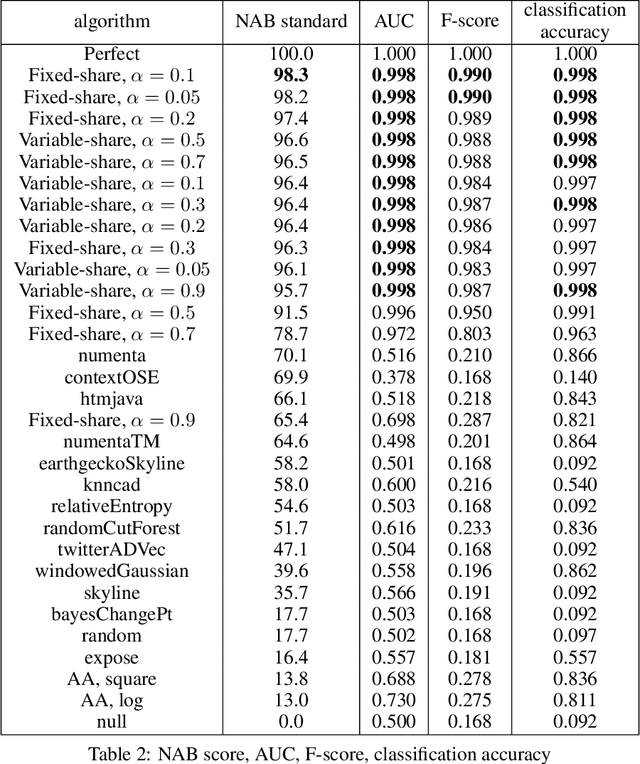
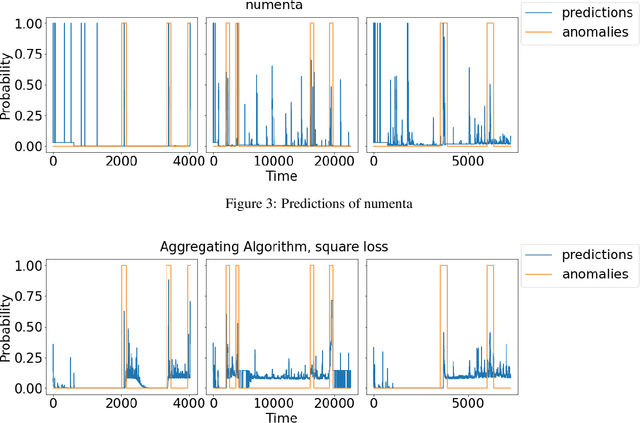
The increasing connectivity of data and cyber-physical systems has resulted in a growing number of cyber attacks. Real-time detection of such attacks, through identification of anomalous activity, is required so that mitigation and contingent actions can be effectively and rapidly deployed. We propose to apply the prediction with expert advice (PEA) framework to a real-time anomaly detection problem. We apply PEA on open-source real datasets and show that the combination of models, which we call experts, provides significantly better results than any single model. An important property of the proposed approaches is their theoretical guarantees that they perform close to the best expert or even the superexpert, which can switch between the best performing experts. In addition, the approaches are also straightforward to implement and require little memory to run on streaming data.
Aggregating Algorithm for Prediction of Packs
Oct 23, 2017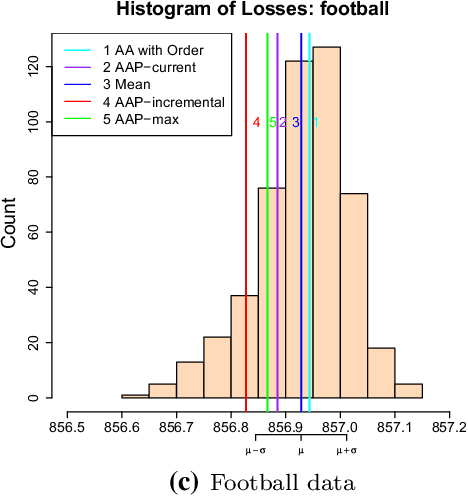
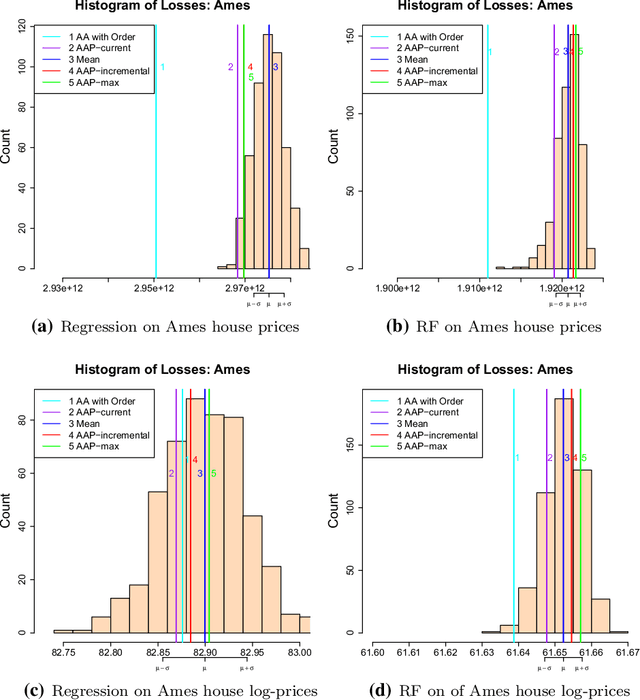
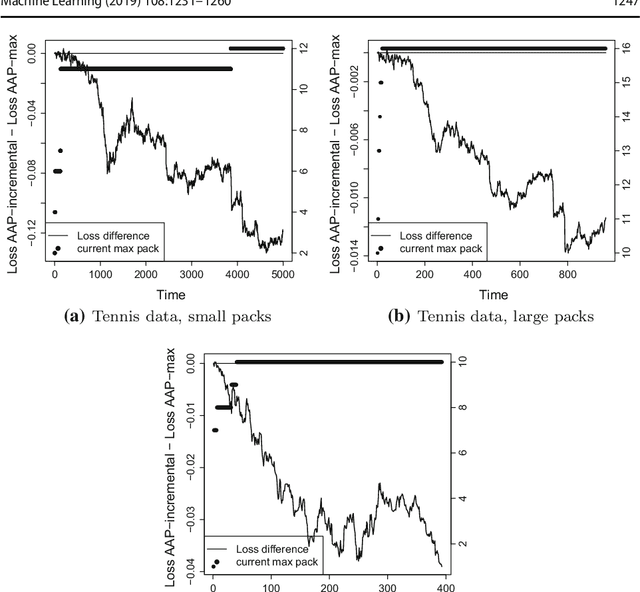
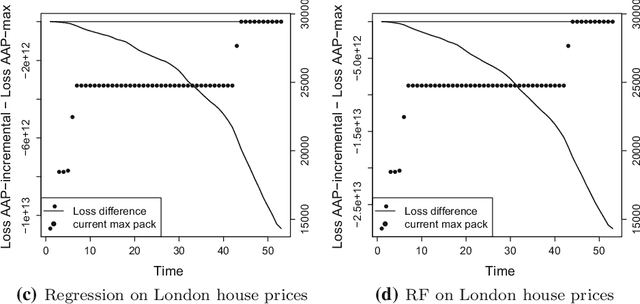
This paper formulates the protocol for prediction of packs, which a special case of prediction under delayed feedback. Under this protocol, the learner must make a few predictions without seeing the outcomes and then the outcomes are revealed. We develop the theory of prediction with expert advice for packs. By applying Vovk's Aggregating Algorithm to this problem we obtain a number of algorithms with tight upper bounds. We carry out empirical experiments on housing data.