 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSISA: Securing Images by Selective Alteration
Jun 20, 2021
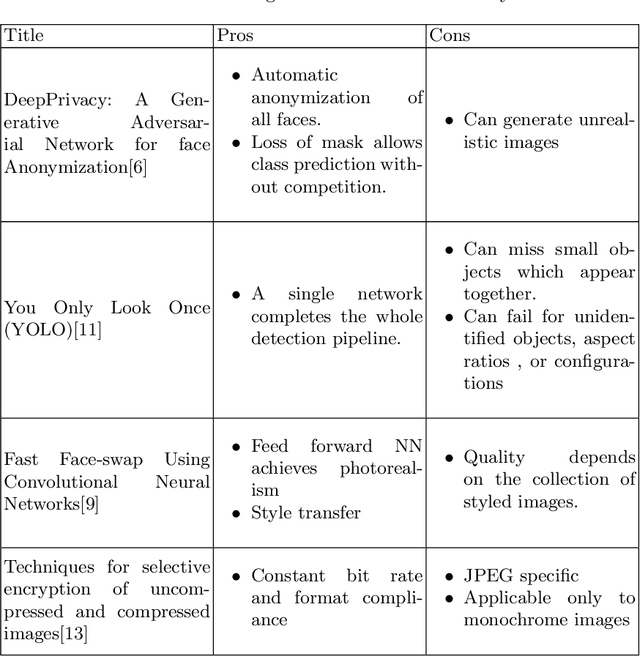


With an increase in mobile and camera devices' popularity, digital content in the form of images has increased drastically. As personal life is being continuously documented in pictures, the risk of losing it to eavesdroppers is a matter of grave concern. Secondary storage is the most preferred medium for the storage of personal and other images. Our work is concerned with the security of such images. While encryption is the best way to ensure image security, full encryption and decryption is a computationally-intensive process. Moreover, as cameras are getting better every day, image quality, and thus, the pixel density has increased considerably. The increased pixel density makes encryption and decryption more expensive. We, therefore, delve into selective encryption and selective blurring based on the region of interest. Instead of encrypting or blurring the entire photograph, we only encode selected regions of the image. We present a comparative analysis of the partial and full encryption of the photos. This kind of encoding will help us lower the encryption overhead without compromising security. The applications utilizing this technique will become more usable due to the reduction in the decryption time. Additionally, blurred images being more readable than encrypted ones, allowed us to define the level of security. We leverage the machine learning algorithms like Mask-RCNN (Region-based convolutional neural network) and YOLO (You Only Look Once) to select the region of interest. These algorithms have set new benchmarks for object recognition. We develop an end to end system to demonstrate our idea of selective encryption.
ShufText: A Simple Black Box Approach to Evaluate the Fragility of Text Classification Models
Jan 30, 2021
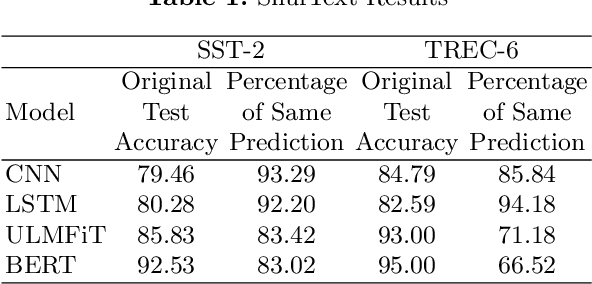
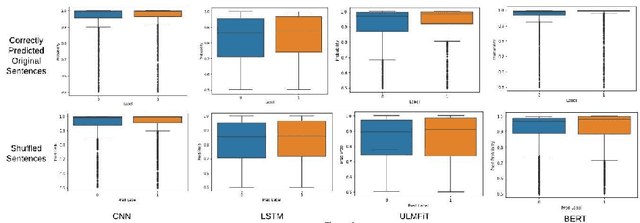
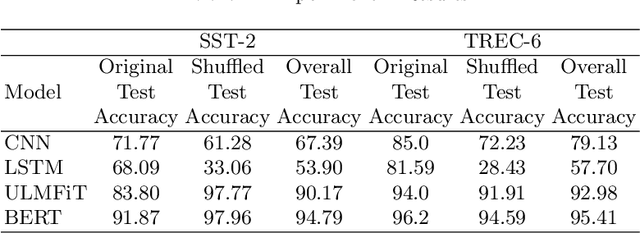
Text classification is the most basic natural language processing task. It has a wide range of applications ranging from sentiment analysis to topic classification. Recently, deep learning approaches based on CNN, LSTM, and Transformers have been the de facto approach for text classification. In this work, we highlight a common issue associated with these approaches. We show that these systems are over-reliant on the important words present in the text that are useful for classification. With limited training data and discriminative training strategy, these approaches tend to ignore the semantic meaning of the sentence and rather just focus on keywords or important n-grams. We propose a simple black box technique ShutText to present the shortcomings of the model and identify the over-reliance of the model on keywords. This involves randomly shuffling the words in a sentence and evaluating the classification accuracy. We see that on common text classification datasets there is very little effect of shuffling and with high probability these models predict the original class. We also evaluate the effect of language model pretraining on these models and try to answer questions around model robustness to out of domain sentences. We show that simple models based on CNN or LSTM as well as complex models like BERT are questionable in terms of their syntactic and semantic understanding.