 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA New Framework for Distributed Submodular Maximization
Aug 11, 2016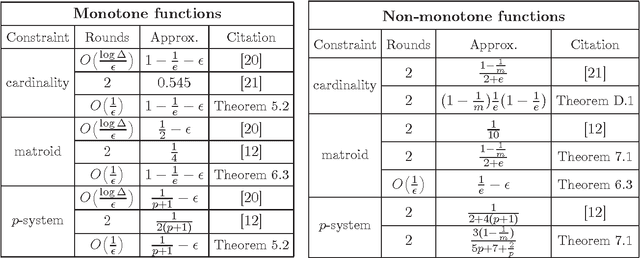



A wide variety of problems in machine learning, including exemplar clustering, document summarization, and sensor placement, can be cast as constrained submodular maximization problems. A lot of recent effort has been devoted to developing distributed algorithms for these problems. However, these results suffer from high number of rounds, suboptimal approximation ratios, or both. We develop a framework for bringing existing algorithms in the sequential setting to the distributed setting, achieving near optimal approximation ratios for many settings in only a constant number of MapReduce rounds. Our techniques also give a fast sequential algorithm for non-monotone maximization subject to a matroid constraint.
The Power of Randomization: Distributed Submodular Maximization on Massive Datasets
Apr 22, 2015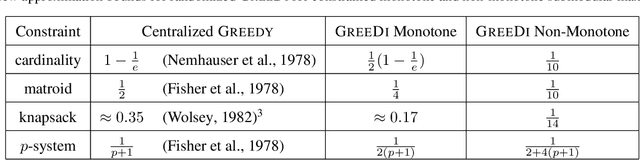
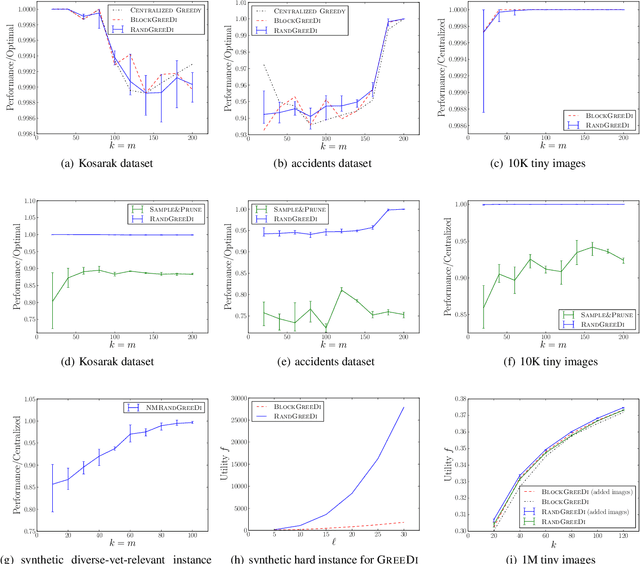
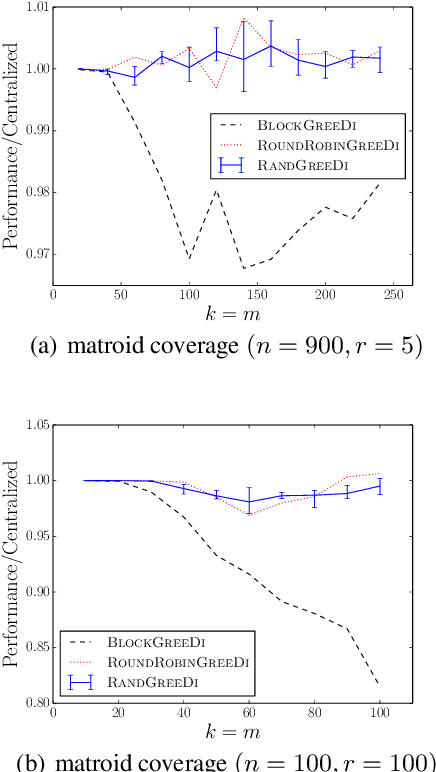
A wide variety of problems in machine learning, including exemplar clustering, document summarization, and sensor placement, can be cast as constrained submodular maximization problems. Unfortunately, the resulting submodular optimization problems are often too large to be solved on a single machine. We develop a simple distributed algorithm that is embarrassingly parallel and it achieves provable, constant factor, worst-case approximation guarantees. In our experiments, we demonstrate its efficiency in large problems with different kinds of constraints with objective values always close to what is achievable in the centralized setting.