 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling Variational Autoencoders
Nov 14, 2022A variational autoencoder (VAE) is a probabilistic machine learning framework for posterior inference that projects an input set of high-dimensional data to a lower-dimensional, latent space. The latent space learned with a VAE offers exciting opportunities to develop new data-driven design processes in creative disciplines, in particular, to automate the generation of multiple novel designs that are aesthetically reminiscent of the input data but that were unseen during training. However, the learned latent space is typically disorganized and entangled: traversing the latent space along a single dimension does not result in changes to single visual attributes of the data. The lack of latent structure impedes designers from deliberately controlling the visual attributes of new designs generated from the latent space. This paper presents an experimental study that investigates latent space disentanglement. We implement three different VAE models from the literature and train them on a publicly available dataset of 60,000 images of hand-written digits. We perform a sensitivity analysis to find a small number of latent dimensions necessary to maximize a lower bound to the log marginal likelihood of the data. Furthermore, we investigate the trade-offs between the quality of the reconstruction of the decoded images and the level of disentanglement of the latent space. We are able to automatically align three latent dimensions with three interpretable visual properties of the digits: line weight, tilt and width. Our experiments suggest that i) increasing the contribution of the Kullback-Leibler divergence between the prior over the latents and the variational distribution to the evidence lower bound, and ii) conditioning input image class enhances the learning of a disentangled latent space with a VAE.
Three Cooperative Robotic Fabrication Methods for the Scaffold-Free Construction of a Masonry Arch
Apr 10, 2021
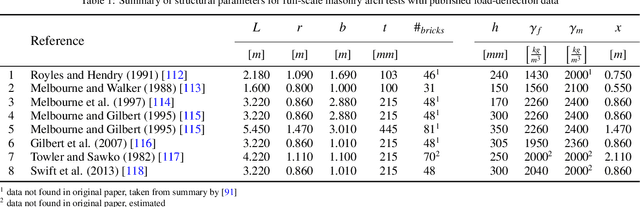
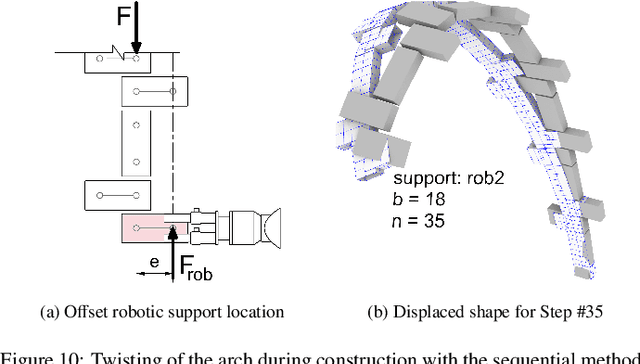
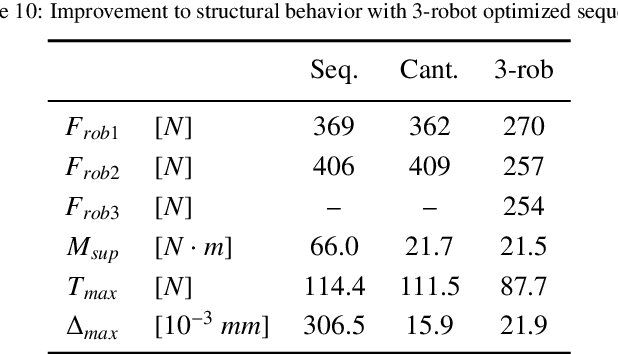
Geometrically complex masonry structures (e.g., arches, domes, vaults) are traditionally built with expensive scaffolding or falsework to provide stability during construction. The process of building such structures can potentially be improved through the use of multiple robots working together in a cooperative assembly framework. Here a robot is envisioned as both a placement and external support agent during fabrication - the unfinished structure is supported in such a way that scaffolding is not required. The goal of this paper is to present and validate the efficacy of three cooperative fabrication approaches using two or three robots, for the scaffold-free construction of a stable masonry arch from which a medium-span vault is built. A simplified numerical method to represent a masonry structure is first presented and validated to analyse systems composed of discrete volumetric elements. This method is then used to evaluate the effect of the three cooperative robotic fabrication strategies on the stability performance of the central arch. The sequential method and cantilever method, which utilize two robotic arms, are shown to be viable methods, but have challenges related to scalability and robustness. By adding a third robotic agent, it becomes possible to determine a structurally optimal fabrication sequence through a multi-objective optimization process. The optimized three robot method is shown to significantly improve the structural behavior over all fabrication steps. The modeling approaches presented in this paper are broadly formulated and widely applicable for the analysis of cooperative robotic fabrication sequences for the construction of discrete element structures across scales and materials.