 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Embedding Techniques in Multimodal Machine Learning for Mental Illness Assessment
Apr 02, 2025



The increasing global prevalence of mental disorders, such as depression and PTSD, requires objective and scalable diagnostic tools. Traditional clinical assessments often face limitations in accessibility, objectivity, and consistency. This paper investigates the potential of multimodal machine learning to address these challenges, leveraging the complementary information available in text, audio, and video data. Our approach involves a comprehensive analysis of various data preprocessing techniques, including novel chunking and utterance-based formatting strategies. We systematically evaluate a range of state-of-the-art embedding models for each modality and employ Convolutional Neural Networks (CNNs) and Bidirectional LSTM Networks (BiLSTMs) for feature extraction. We explore data-level, feature-level, and decision-level fusion techniques, including a novel integration of Large Language Model (LLM) predictions. We also investigate the impact of replacing Multilayer Perceptron classifiers with Support Vector Machines. We extend our analysis to severity prediction using PHQ-8 and PCL-C scores and multi-class classification (considering co-occurring conditions). Our results demonstrate that utterance-based chunking significantly improves performance, particularly for text and audio modalities. Decision-level fusion, incorporating LLM predictions, achieves the highest accuracy, with a balanced accuracy of 94.8% for depression and 96.2% for PTSD detection. The combination of CNN-BiLSTM architectures with utterance-level chunking, coupled with the integration of external LLM, provides a powerful and nuanced approach to the detection and assessment of mental health conditions. Our findings highlight the potential of MMML for developing more accurate, accessible, and personalized mental healthcare tools.
Leveraging Audio and Text Modalities in Mental Health: A Study of LLMs Performance
Dec 09, 2024



Mental health disorders are increasingly prevalent worldwide, creating an urgent need for innovative tools to support early diagnosis and intervention. This study explores the potential of Large Language Models (LLMs) in multimodal mental health diagnostics, specifically for detecting depression and Post Traumatic Stress Disorder through text and audio modalities. Using the E-DAIC dataset, we compare text and audio modalities to investigate whether LLMs can perform equally well or better with audio inputs. We further examine the integration of both modalities to determine if this can enhance diagnostic accuracy, which generally results in improved performance metrics. Our analysis specifically utilizes custom-formulated metrics; Modal Superiority Score and Disagreement Resolvement Score to evaluate how combined modalities influence model performance. The Gemini 1.5 Pro model achieves the highest scores in binary depression classification when using the combined modality, with an F1 score of 0.67 and a Balanced Accuracy (BA) of 77.4%, assessed across the full dataset. These results represent an increase of 3.1% over its performance with the text modality and 2.7% over the audio modality, highlighting the effectiveness of integrating modalities to enhance diagnostic accuracy. Notably, all results are obtained in zero-shot inferring, highlighting the robustness of the models without requiring task-specific fine-tuning. To explore the impact of different configurations on model performance, we conduct binary, severity, and multiclass tasks using both zero-shot and few-shot prompts, examining the effects of prompt variations on performance. The results reveal that models such as Gemini 1.5 Pro in text and audio modalities, and GPT-4o mini in the text modality, often surpass other models in balanced accuracy and F1 scores across multiple tasks.
Automated Multi-Label Annotation for Mental Health Illnesses Using Large Language Models
Dec 05, 2024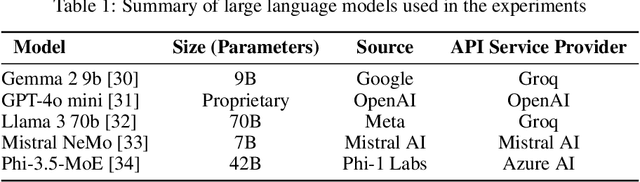



The growing prevalence and complexity of mental health disorders present significant challenges for accurate diagnosis and treatment, particularly in understanding the interplay between co-occurring conditions. Mental health disorders, such as depression and Anxiety, often co-occur, yet current datasets derived from social media posts typically focus on single-disorder labels, limiting their utility in comprehensive diagnostic analyses. This paper addresses this critical gap by proposing a novel methodology for cleaning, sampling, labeling, and combining data to create versatile multi-label datasets. Our approach introduces a synthetic labeling technique to transform single-label datasets into multi-label annotations, capturing the complexity of overlapping mental health conditions. To achieve this, two single-label datasets are first merged into a foundational multi-label dataset, enabling realistic analyses of co-occurring diagnoses. We then design and evaluate various prompting strategies for large language models (LLMs), ranging from single-label predictions to unrestricted prompts capable of detecting any present disorders. After rigorously assessing multiple LLMs and prompt configurations, the optimal combinations are identified and applied to label six additional single-disorder datasets from RMHD. The result is SPAADE-DR, a robust, multi-label dataset encompassing diverse mental health conditions. This research demonstrates the transformative potential of LLM-driven synthetic labeling in advancing mental health diagnostics from social media data, paving the way for more nuanced, data-driven insights into mental health care.