 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Multi-Label Annotation for Mental Health Illnesses Using Large Language Models
Paper and Code
Dec 05, 2024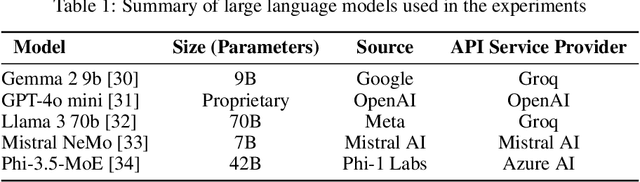



The growing prevalence and complexity of mental health disorders present significant challenges for accurate diagnosis and treatment, particularly in understanding the interplay between co-occurring conditions. Mental health disorders, such as depression and Anxiety, often co-occur, yet current datasets derived from social media posts typically focus on single-disorder labels, limiting their utility in comprehensive diagnostic analyses. This paper addresses this critical gap by proposing a novel methodology for cleaning, sampling, labeling, and combining data to create versatile multi-label datasets. Our approach introduces a synthetic labeling technique to transform single-label datasets into multi-label annotations, capturing the complexity of overlapping mental health conditions. To achieve this, two single-label datasets are first merged into a foundational multi-label dataset, enabling realistic analyses of co-occurring diagnoses. We then design and evaluate various prompting strategies for large language models (LLMs), ranging from single-label predictions to unrestricted prompts capable of detecting any present disorders. After rigorously assessing multiple LLMs and prompt configurations, the optimal combinations are identified and applied to label six additional single-disorder datasets from RMHD. The result is SPAADE-DR, a robust, multi-label dataset encompassing diverse mental health conditions. This research demonstrates the transformative potential of LLM-driven synthetic labeling in advancing mental health diagnostics from social media data, paving the way for more nuanced, data-driven insights into mental health care.