 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge-Instruct: Effective Continual Pre-training from Limited Data using Instructions
Apr 08, 2025



While Large Language Models (LLMs) acquire vast knowledge during pre-training, they often lack domain-specific, new, or niche information. Continual pre-training (CPT) attempts to address this gap but suffers from catastrophic forgetting and inefficiencies in low-data regimes. We introduce Knowledge-Instruct, a novel approach to efficiently inject knowledge from limited corpora through pure instruction-tuning. By generating information-dense synthetic instruction data, it effectively integrates new knowledge while preserving general reasoning and instruction-following abilities. Knowledge-Instruct demonstrates superior factual memorization, minimizes catastrophic forgetting, and remains scalable by leveraging synthetic data from relatively small language models. Additionally, it enhances contextual understanding, including complex multi-hop reasoning, facilitating integration with retrieval systems. We validate its effectiveness across diverse benchmarks, including Companies, a new dataset that we release to measure knowledge injection capabilities.
SECQUE: A Benchmark for Evaluating Real-World Financial Analysis Capabilities
Apr 06, 2025



We introduce SECQUE, a comprehensive benchmark for evaluating large language models (LLMs) in financial analysis tasks. SECQUE comprises 565 expert-written questions covering SEC filings analysis across four key categories: comparison analysis, ratio calculation, risk assessment, and financial insight generation. To assess model performance, we develop SECQUE-Judge, an evaluation mechanism leveraging multiple LLM-based judges, which demonstrates strong alignment with human evaluations. Additionally, we provide an extensive analysis of various models' performance on our benchmark. By making SECQUE publicly available, we aim to facilitate further research and advancements in financial AI.
Mixing It Up: The Cocktail Effect of Multi-Task Fine-Tuning on LLM Performance -- A Case Study in Finance
Oct 01, 2024


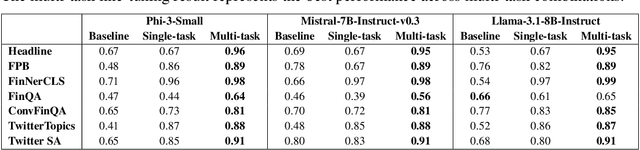
The application of large language models (LLMs) in domain-specific contexts, including finance, has expanded rapidly. Domain-specific LLMs are typically evaluated based on their performance in various downstream tasks relevant to the domain. In this work, we present a detailed analysis of fine-tuning LLMs for such tasks. Somewhat counterintuitively, we find that in domain-specific cases, fine-tuning exclusively on the target task is not always the most effective strategy. Instead, multi-task fine-tuning - where models are trained on a cocktail of related tasks - can significantly enhance performance. We demonstrate how this approach enables a small model, such as Phi-3-Mini, to achieve state-of-the-art results, even surpassing the much larger GPT-4-o model on financial benchmarks. Our study involves a large-scale experiment, training over 200 models using several widely adopted LLMs as baselines, and empirically confirms the benefits of multi-task fine-tuning. Additionally, we explore the use of general instruction data as a form of regularization, suggesting that it helps minimize performance degradation. We also investigate the inclusion of mathematical data, finding improvements in numerical reasoning that transfer effectively to financial tasks. Finally, we note that while fine-tuning for downstream tasks leads to targeted improvements in task performance, it does not necessarily result in broader gains in domain knowledge or complex domain reasoning abilities.