 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixing It Up: The Cocktail Effect of Multi-Task Fine-Tuning on LLM Performance -- A Case Study in Finance
Paper and Code
Oct 01, 2024


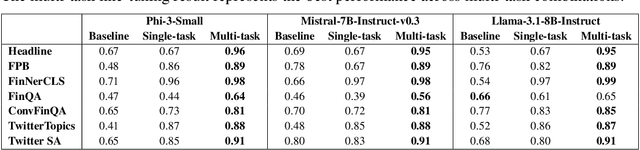
The application of large language models (LLMs) in domain-specific contexts, including finance, has expanded rapidly. Domain-specific LLMs are typically evaluated based on their performance in various downstream tasks relevant to the domain. In this work, we present a detailed analysis of fine-tuning LLMs for such tasks. Somewhat counterintuitively, we find that in domain-specific cases, fine-tuning exclusively on the target task is not always the most effective strategy. Instead, multi-task fine-tuning - where models are trained on a cocktail of related tasks - can significantly enhance performance. We demonstrate how this approach enables a small model, such as Phi-3-Mini, to achieve state-of-the-art results, even surpassing the much larger GPT-4-o model on financial benchmarks. Our study involves a large-scale experiment, training over 200 models using several widely adopted LLMs as baselines, and empirically confirms the benefits of multi-task fine-tuning. Additionally, we explore the use of general instruction data as a form of regularization, suggesting that it helps minimize performance degradation. We also investigate the inclusion of mathematical data, finding improvements in numerical reasoning that transfer effectively to financial tasks. Finally, we note that while fine-tuning for downstream tasks leads to targeted improvements in task performance, it does not necessarily result in broader gains in domain knowledge or complex domain reasoning abilities.