 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimax Limits of k-Fold Cross-Validation via Majority
May 25, 2026We study the mean-squared error of $k$-fold cross-validation as a risk estimator, with particular emphasis on how its accuracy depends on the number of folds $k$. Despite the widespread use of cross-validation, principled guidance for choosing $k$ is largely absent, mainly due to the complex dependence between fold-wise error estimates. To obtain sharp and interpretable results, we focus on the majority algorithm in binary classification, a minimal yet nontrivial empirical risk minimization procedure. We provide a fine-grained analysis of its cross-validation behavior, showing that even this simple algorithm exhibits subtle and delicate phenomena for which existing theory provides loose and even vacuous bounds. Leveraging this analysis, we introduce a minimax framework for cross-validation risk estimation and prove that no empirical risk minimization algorithm can achieve an $O(1/n)$ minimax mean-squared error when the number of folds grows with the number of samples $n$; instead, a lower bound of order $Ω(\sqrt{k}/n)$ is unavoidable. Our results reveal fundamental limitations of cross-validation as a data-reuse strategy, clarify gaps and inaccuracies in prior theoretical work, and position the majority algorithm as a natural benchmark that any tight analysis of cross-validation should be able to explain.
The Structure of Cross-Validation Error: Stability, Covariance, and Minimax Limits
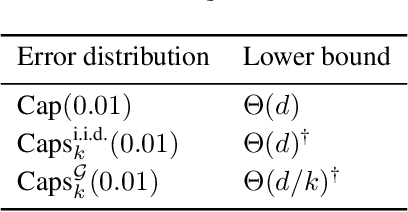
Nov 05, 2025Despite ongoing theoretical research on cross-validation (CV), many theoretical questions about CV remain widely open. This motivates our investigation into how properties of algorithm-distribution pairs can affect the choice for the number of folds in $k$-fold cross-validation. Our results consist of a novel decomposition of the mean-squared error of cross-validation for risk estimation, which explicitly captures the correlations of error estimates across overlapping folds and includes a novel algorithmic stability notion, squared loss stability, that is considerably weaker than the typically required hypothesis stability in other comparable works. Furthermore, we prove: 1. For every learning algorithm that minimizes empirical error, a minimax lower bound on the mean-squared error of $k$-fold CV estimating the population risk $L_\mathcal{D}$: \[ \min_{k \mid n}\; \max_{\mathcal{D}}\; \mathbb{E}\!\left[\big(\widehat{L}_{\mathrm{CV}}^{(k)} - L_{\mathcal{D}}\big)^{2}\right] \;=\; \Omega\!\big(\sqrt{k}/n\big), \] where $n$ is the sample size and $k$ the number of folds. This shows that even under idealized conditions, for large values of $k$, CV cannot attain the optimum of order $1/n$ achievable by a validation set of size $n$, reflecting an inherent penalty caused by dependence between folds. 2. Complementing this, we exhibit learning rules for which \[ \max_{\mathcal{D}}\; \mathbb{E}\!\left[\big(\widehat{L}_{\mathrm{CV}}^{(k)} - L_{\mathcal{D}}\big)^{2}\right] \;=\; \Omega(k/n), \] matching (up to constants) the accuracy of a hold-out estimator of a single fold of size $n/k$. Together these results delineate the fundamental trade-off in resampling-based risk estimation: CV cannot fully exploit all $n$ samples for unbiased risk evaluation, and its minimax performance is pinned between the $k/n$ and $\sqrt{k}/n$ regimes.
Efficient Machine Unlearning by Model Splitting and Core Sample Selection
May 11, 2025Machine unlearning is essential for meeting legal obligations such as the right to be forgotten, which requires the removal of specific data from machine learning models upon request. While several approaches to unlearning have been proposed, existing solutions often struggle with efficiency and, more critically, with the verification of unlearning - particularly in the case of weak unlearning guarantees, where verification remains an open challenge. We introduce a generalized variant of the standard unlearning metric that enables more efficient and precise unlearning strategies. We also present an unlearning-aware training procedure that, in many cases, allows for exact unlearning. We term our approach MaxRR. When exact unlearning is not feasible, MaxRR still supports efficient unlearning with properties closely matching those achieved through full retraining.
Federated One-Shot Learning with Data Privacy and Objective-Hiding
Apr 29, 2025Privacy in federated learning is crucial, encompassing two key aspects: safeguarding the privacy of clients' data and maintaining the privacy of the federator's objective from the clients. While the first aspect has been extensively studied, the second has received much less attention. We present a novel approach that addresses both concerns simultaneously, drawing inspiration from techniques in knowledge distillation and private information retrieval to provide strong information-theoretic privacy guarantees. Traditional private function computation methods could be used here; however, they are typically limited to linear or polynomial functions. To overcome these constraints, our approach unfolds in three stages. In stage 0, clients perform the necessary computations locally. In stage 1, these results are shared among the clients, and in stage 2, the federator retrieves its desired objective without compromising the privacy of the clients' data. The crux of the method is a carefully designed protocol that combines secret-sharing-based multi-party computation and a graph-based private information retrieval scheme. We show that our method outperforms existing tools from the literature when properly adapted to this setting.
Noether: The More Things Change, the More Stay the Same
Apr 12, 2021
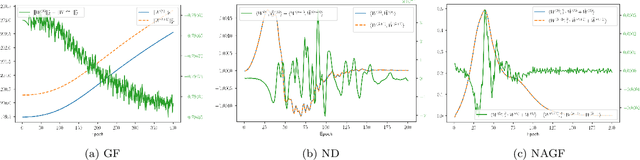

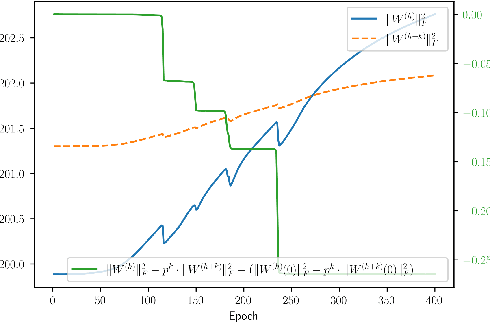
Symmetries have proven to be important ingredients in the analysis of neural networks. So far their use has mostly been implicit or seemingly coincidental. We undertake a systematic study of the role that symmetry plays. In particular, we clarify how symmetry interacts with the learning algorithm. The key ingredient in our study is played by Noether's celebrated theorem which, informally speaking, states that symmetry leads to conserved quantities (e.g., conservation of energy or conservation of momentum). In the realm of neural networks under gradient descent, model symmetries imply restrictions on the gradient path. E.g., we show that symmetry of activation functions leads to boundedness of weight matrices, for the specific case of linear activations it leads to balance equations of consecutive layers, data augmentation leads to gradient paths that have "momentum"-type restrictions, and time symmetry leads to a version of the Neural Tangent Kernel. Symmetry alone does not specify the optimization path, but the more symmetries are contained in the model the more restrictions are imposed on the path. Since symmetry also implies over-parametrization, this in effect implies that some part of this over-parametrization is cancelled out by the existence of the conserved quantities. Symmetry can therefore be thought of as one further important tool in understanding the performance of neural networks under gradient descent.
Adversarial Robustness: What fools you makes you stronger
Feb 18, 2021
We prove an exponential separation for the sample complexity between the standard PAC-learning model and a version of the Equivalence-Query-learning model. We then show that this separation has interesting implications for adversarial robustness. We explore a vision of designing an adaptive defense that in the presence of an attacker computes a model that is provably robust. In particular, we show how to realize this vision in a simplified setting. In order to do so, we introduce a notion of a strong adversary: he is not limited by the type of perturbations he can apply but when presented with a classifier can repetitively generate different adversarial examples. We explain why this notion is interesting to study and use it to prove the following. There exists an efficient adversarial-learning-like scheme such that for every strong adversary $\mathbf{A}$ it outputs a classifier that (a) cannot be strongly attacked by $\mathbf{A}$, or (b) has error at most $\epsilon$. In both cases our scheme uses exponentially (in $\epsilon$) fewer samples than what the PAC bound requires.
Query complexity of adversarial attacks
Oct 02, 2020
Modern machine learning models are typically highly accurate but have been shown to be vulnerable to small, adversarially-chosen perturbations of the input. There are two main models of attacks considered in the literature: black-box and white-box. We consider these threat models as two ends of a fine-grained spectrum, indexed by the number of queries the adversary can ask. Using this point of view we investigate how many queries the adversary needs to make to design an attack that is comparable to the best possible attack in the white-box model. We analyze two classical learning algorithms on two synthetic tasks for which we prove meaningful security guarantees. The obtained bounds suggest that some learning algorithms are inherently more robust against query-bounded adversaries than others.
Constructing a provably adversarially-robust classifier from a high accuracy one
Dec 16, 2019Modern machine learning models with very high accuracy have been shown to be vulnerable to small, adversarially chosen perturbations of the input. Given black-box access to a high-accuracy classifier $f$, we show how to construct a new classifier $g$ that has high accuracy and is also robust to adversarial $\ell_2$-bounded perturbations. Our algorithm builds upon the framework of \textit{randomized smoothing} that has been recently shown to outperform all previous defenses against $\ell_2$-bounded adversaries. Using techniques like random partitions and doubling dimension, we are able to bound the adversarial error of $g$ in terms of the optimum error. In this paper we focus on our conceptual contribution, but we do present two examples to illustrate our framework. We will argue that, under some assumptions, our bounds are optimal for these cases.