 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQualitative detection of oil adulteration with machine learning approaches
May 14, 2013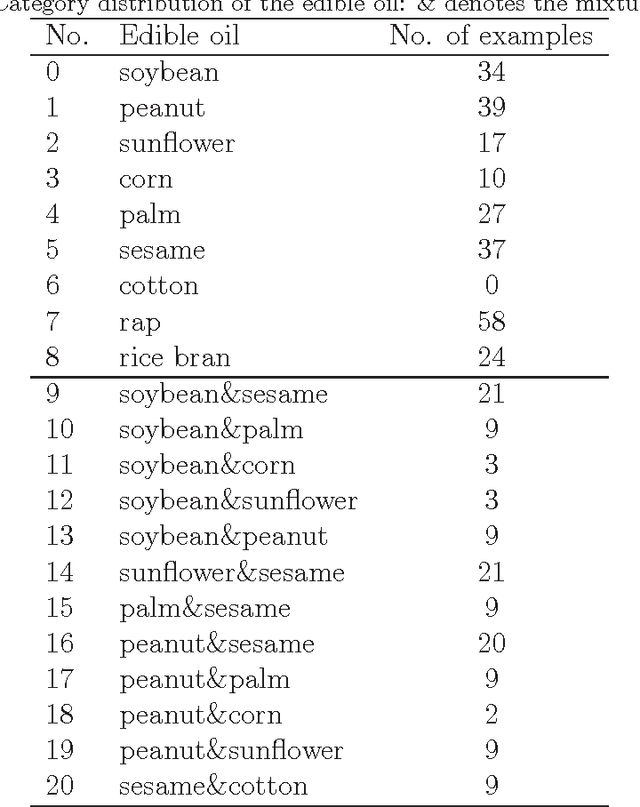
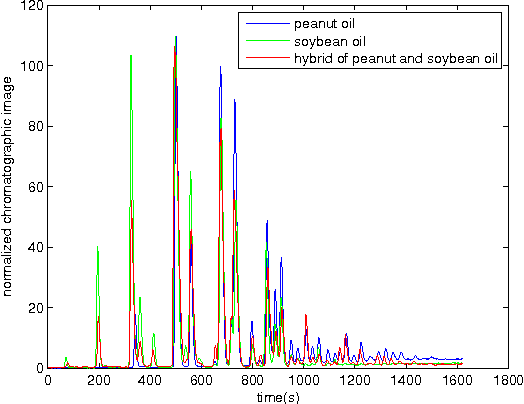
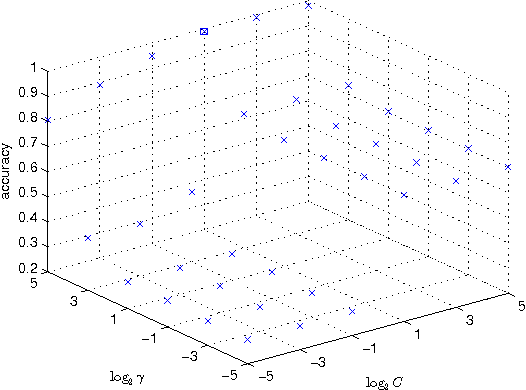

The study focused on the machine learning analysis approaches to identify the adulteration of 9 kinds of edible oil qualitatively and answered the following three questions: Is the oil sample adulterant? How does it constitute? What is the main ingredient of the adulteration oil? After extracting the high-performance liquid chromatography (HPLC) data on triglyceride from 370 oil samples, we applied the adaptive boosting with multi-class Hamming loss (AdaBoost.MH) to distinguish the oil adulteration in contrast with the support vector machine (SVM). Further, we regarded the adulterant oil and the pure oil samples as ones with multiple labels and with only one label, respectively. Then multi-label AdaBoost.MH and multi-label learning vector quantization (ML-LVQ) model were built to determine the ingredients and their relative ratio in the adulteration oil. The experimental results on six measures show that ML-LVQ achieves better performance than multi-label AdaBoost.MH.