 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnbiased Visual Reasoning with Controlled Visual Inputs
Dec 19, 2025End-to-end Vision-language Models (VLMs) often answer visual questions by exploiting spurious correlations instead of causal visual evidence, and can become more shortcut-prone when fine-tuned. We introduce VISTA (Visual-Information Separation for Text-based Analysis), a modular framework that decouples perception from reasoning via an explicit information bottleneck. A frozen VLM sensor is restricted to short, objective perception queries, while a text-only LLM reasoner decomposes each question, plans queries, and aggregates visual facts in natural language. This controlled interface defines a reward-aligned environment for training unbiased visual reasoning with reinforcement learning. Instantiated with Qwen2.5-VL and Llama3.2-Vision sensors, and trained with GRPO from only 641 curated multi-step questions, VISTA significantly improves robustness to real-world spurious correlations on SpuriVerse (+16.29% with Qwen-2.5-VL-7B and +6.77% with Llama-3.2-Vision-11B), while remaining competitive on MMVP and a balanced SeedBench subset. VISTA transfers robustly across unseen VLM sensors and is able to recognize and recover from VLM perception failures. Human analysis further shows that VISTA's reasoning traces are more neutral, less reliant on spurious attributes, and more explicitly grounded in visual evidence than end-to-end VLM baselines.
AdapMTL: Adaptive Pruning Framework for Multitask Learning Model
Aug 07, 2024In the domain of multimedia and multimodal processing, the efficient handling of diverse data streams such as images, video, and sensor data is paramount. Model compression and multitask learning (MTL) are crucial in this field, offering the potential to address the resource-intensive demands of processing and interpreting multiple forms of media simultaneously. However, effectively compressing a multitask model presents significant challenges due to the complexities of balancing sparsity allocation and accuracy performance across multiple tasks. To tackle these challenges, we propose AdapMTL, an adaptive pruning framework for MTL models. AdapMTL leverages multiple learnable soft thresholds independently assigned to the shared backbone and the task-specific heads to capture the nuances in different components' sensitivity to pruning. During training, it co-optimizes the soft thresholds and MTL model weights to automatically determine the suitable sparsity level at each component to achieve both high task accuracy and high overall sparsity. It further incorporates an adaptive weighting mechanism that dynamically adjusts the importance of task-specific losses based on each task's robustness to pruning. We demonstrate the effectiveness of AdapMTL through comprehensive experiments on popular multitask datasets, namely NYU-v2 and Tiny-Taskonomy, with different architectures, showcasing superior performance compared to state-of-the-art pruning methods.
Rethinking Hard-Parameter Sharing in Multi-Task Learning
Jul 23, 2021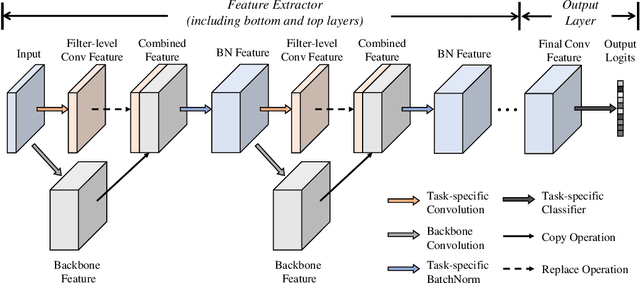
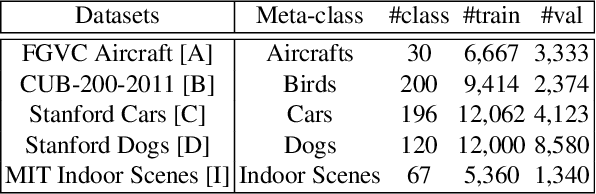
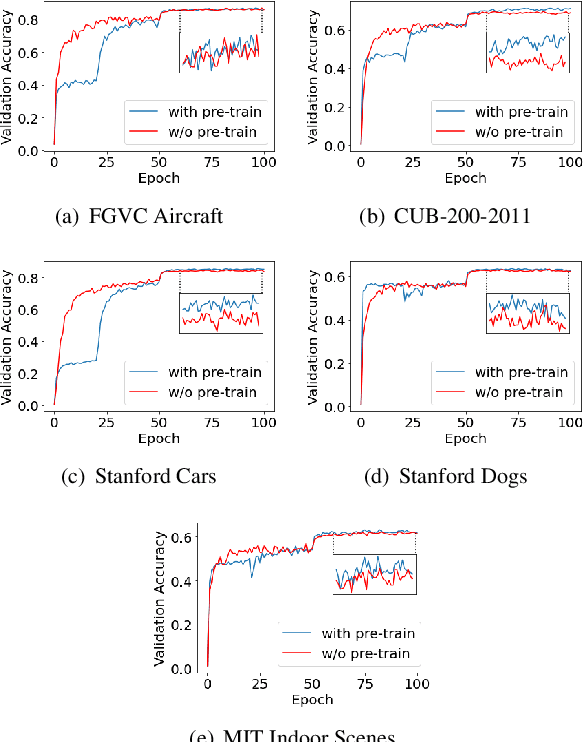
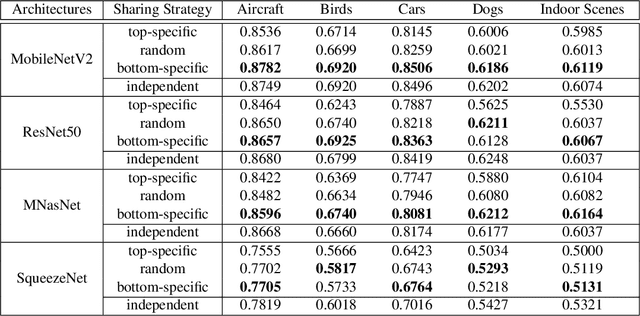
Hard parameter sharing in multi-task learning (MTL) allows tasks to share some of model parameters, reducing storage cost and improving prediction accuracy. The common sharing practice is to share bottom layers of a deep neural network among tasks while using separate top layers for each task. In this work, we revisit this common practice via an empirical study on fine-grained image classification tasks and make two surprising observations. (1) Using separate bottom-layer parameters could achieve significantly better performance than the common practice and this phenomenon holds for different number of tasks jointly trained on different backbone architectures with different quantity of task-specific parameters. (2) A multi-task model with a small proportion of task-specific parameters from bottom layers can achieve competitive performance with independent models trained on each task separately and outperform a state-of-the-art MTL framework. Our observations suggest that people rethink the current sharing paradigm and adopt the new strategy of using separate bottom-layer parameters as a stronger baseline for model design in MTL.