 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralization Bounds for Transformer Channel Decoders
Jan 11, 2026Transformer channel decoders, such as the Error Correction Code Transformer (ECCT), have shown strong empirical performance in channel decoding, yet their generalization behavior remains theoretically unclear. This paper studies the generalization performance of ECCT from a learning-theoretic perspective. By establishing a connection between multiplicative noise estimation errors and bit-error-rate (BER), we derive an upper bound on the generalization gap via bit-wise Rademacher complexity. The resulting bound characterizes the dependence on code length, model parameters, and training set size, and applies to both single-layer and multi-layer ECCTs. We further show that parity-check-based masked attention induces sparsity that reduces the covering number, leading to a tighter generalization bound. To the best of our knowledge, this work provides the first theoretical generalization guarantees for this class of decoders.
Editable-DeepSC: Reliable Cross-Modal Semantic Communications for Facial Editing
Nov 24, 2024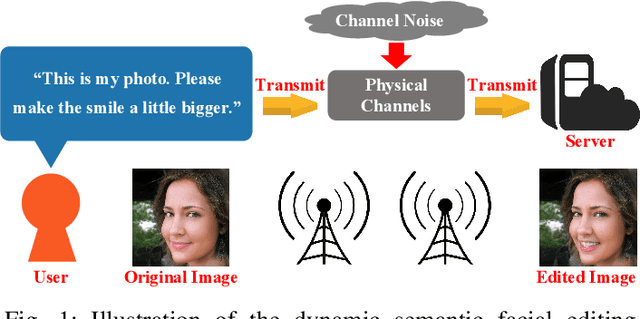


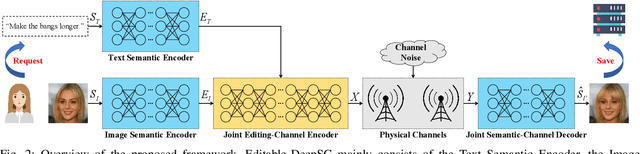
Real-time computer vision (CV) plays a crucial role in various real-world applications, whose performance is highly dependent on communication networks. Nonetheless, the data-oriented characteristics of conventional communications often do not align with the special needs of real-time CV tasks. To alleviate this issue, the recently emerged semantic communications only transmit task-related semantic information and exhibit a promising landscape to address this problem. However, the communication challenges associated with Semantic Facial Editing, one of the most important real-time CV applications on social media, still remain largely unexplored. In this paper, we fill this gap by proposing Editable-DeepSC, a novel cross-modal semantic communication approach for facial editing. Firstly, we theoretically discuss different transmission schemes that separately handle communications and editings, and emphasize the necessity of Joint Editing-Channel Coding (JECC) via iterative attributes matching, which integrates editings into the communication chain to preserve more semantic mutual information. To compactly represent the high-dimensional data, we leverage inversion methods via pre-trained StyleGAN priors for semantic coding. To tackle the dynamic channel noise conditions, we propose SNR-aware channel coding via model fine-tuning. Extensive experiments indicate that Editable-DeepSC can achieve superior editings while significantly saving the transmission bandwidth, even under high-resolution and out-of-distribution (OOD) settings.