 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Learning of the Latent Space of Wasserstein Generative Adversarial Networks
Sep 27, 2024Generative models based on latent variables, such as generative adversarial networks (GANs) and variational auto-encoders (VAEs), have gained lots of interests due to their impressive performance in many fields. However, many data such as natural images usually do not populate the ambient Euclidean space but instead reside in a lower-dimensional manifold. Thus an inappropriate choice of the latent dimension fails to uncover the structure of the data, possibly resulting in mismatch of latent representations and poor generative qualities. Towards addressing these problems, we propose a novel framework called the latent Wasserstein GAN (LWGAN) that fuses the Wasserstein auto-encoder and the Wasserstein GAN so that the intrinsic dimension of the data manifold can be adaptively learned by a modified informative latent distribution. We prove that there exist an encoder network and a generator network in such a way that the intrinsic dimension of the learned encoding distribution is equal to the dimension of the data manifold. We theoretically establish that our estimated intrinsic dimension is a consistent estimate of the true dimension of the data manifold. Meanwhile, we provide an upper bound on the generalization error of LWGAN, implying that we force the synthetic data distribution to be similar to the real data distribution from a population perspective. Comprehensive empirical experiments verify our framework and show that LWGAN is able to identify the correct intrinsic dimension under several scenarios, and simultaneously generate high-quality synthetic data by sampling from the learned latent distribution.
Inferential Wasserstein Generative Adversarial Networks
Sep 13, 2021
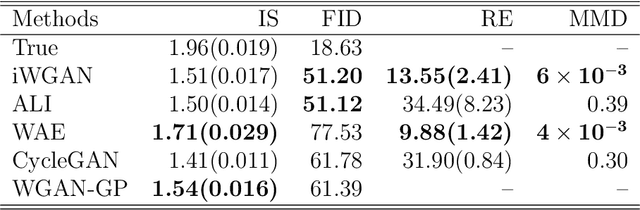

Generative Adversarial Networks (GANs) have been impactful on many problems and applications but suffer from unstable training. The Wasserstein GAN (WGAN) leverages the Wasserstein distance to avoid the caveats in the minmax two-player training of GANs but has other defects such as mode collapse and lack of metric to detect the convergence. We introduce a novel inferential Wasserstein GAN (iWGAN) model, which is a principled framework to fuse auto-encoders and WGANs. The iWGAN model jointly learns an encoder network and a generator network motivated by the iterative primal dual optimization process. The encoder network maps the observed samples to the latent space and the generator network maps the samples from the latent space to the data space. We establish the generalization error bound of the iWGAN to theoretically justify its performance. We further provide a rigorous probabilistic interpretation of our model under the framework of maximum likelihood estimation. The iWGAN, with a clear stopping criteria, has many advantages over other autoencoder GANs. The empirical experiments show that the iWGAN greatly mitigates the symptom of mode collapse, speeds up the convergence, and is able to provide a measurement of quality check for each individual sample. We illustrate the ability of the iWGAN by obtaining competitive and stable performances for benchmark datasets.