 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndirect Gaussian Graph Learning beyond Gaussianity
Oct 25, 2016



This paper studies how to capture dependency graph structures from real data which may not be multivariate Gaussian. Starting from marginal loss functions not necessarily derived from probability distributions, we use an additive over-parametrization with shrinkage to incorporate variable dependencies into the criterion. An iterative Gaussian graph learning algorithm is proposed with ease in implementation. Statistical analysis shows that with the error measured in terms of a proper Bregman divergence, the estimators have fast rate of convergence. Real-life examples in different settings are given to demonstrate the efficacy of the proposed methodology.
Sparse Generalized Principal Component Analysis for Large-scale Applications beyond Gaussianity
Jan 28, 2016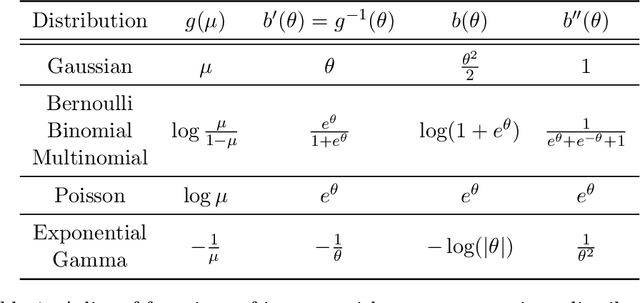
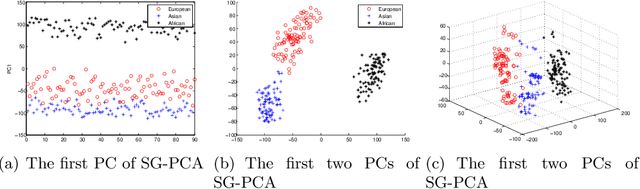
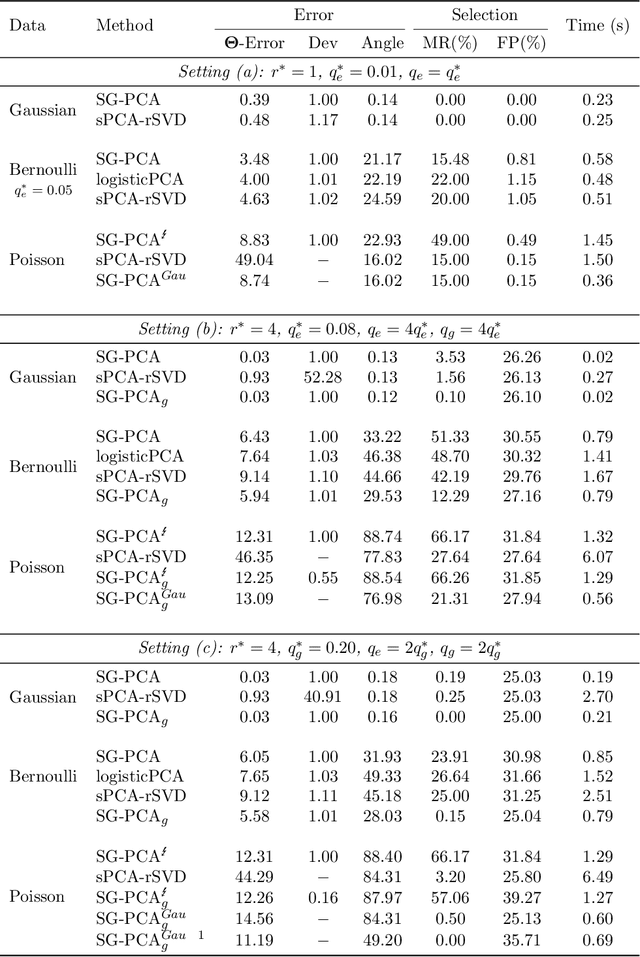
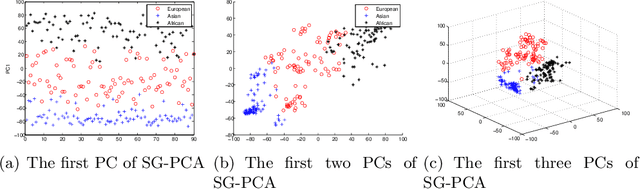
Principal Component Analysis (PCA) is a dimension reduction technique. It produces inconsistent estimators when the dimensionality is moderate to high, which is often the problem in modern large-scale applications where algorithm scalability and model interpretability are difficult to achieve, not to mention the prevalence of missing values. While existing sparse PCA methods alleviate inconsistency, they are constrained to the Gaussian assumption of classical PCA and fail to address algorithm scalability issues. We generalize sparse PCA to the broad exponential family distributions under high-dimensional setup, with built-in treatment for missing values. Meanwhile we propose a family of iterative sparse generalized PCA (SG-PCA) algorithms such that despite the non-convexity and non-smoothness of the optimization task, the loss function decreases in every iteration. In terms of ease and intuitive parameter tuning, our sparsity-inducing regularization is far superior to the popular Lasso. Furthermore, to promote overall scalability, accelerated gradient is integrated for fast convergence, while a progressive screening technique gradually squeezes out nuisance dimensions of a large-scale problem for feasible optimization. High-dimensional simulation and real data experiments demonstrate the efficiency and efficacy of SG-PCA.