 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Urban Flood Prediction using LSTM-DeepLabv3+ and Bayesian Optimization with Spatiotemporal feature fusion
Apr 19, 2023Deep learning models have become increasingly popular for flood prediction due to their superior accuracy and efficiency compared to traditional methods. However, current machine learning methods often rely on separate spatial or temporal feature analysis and have limitations on the types, number, and dimensions of input data. This study presented a CNN-RNN hybrid feature fusion modelling approach for urban flood prediction, which integrated the strengths of CNNs in processing spatial features and RNNs in analyzing different dimensions of time sequences. This approach allowed for both static and dynamic flood predictions. Bayesian optimization was applied to identify the seven most influential flood-driven factors and determine the best combination strategy. By combining four CNNs (FCN, UNet, SegNet, DeepLabv3+) and three RNNs (LSTM, BiLSTM, GRU), the optimal hybrid model was identified as LSTM-DeepLabv3+. This model achieved the highest prediction accuracy (MAE, RMSE, NSE, and KGE were 0.007, 0.025, 0.973 and 0.755, respectively) under various rainfall input conditions. Additionally, the processing speed was significantly improved, with an inference time of 1.158s (approximately 1/125 of the traditional computation time) compared to the physically-based models.
A statistical test for correspondence of texts to the Zipf-Mandelbrot law
Dec 25, 2019

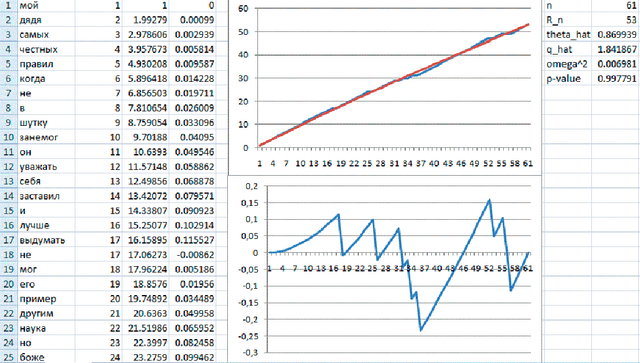
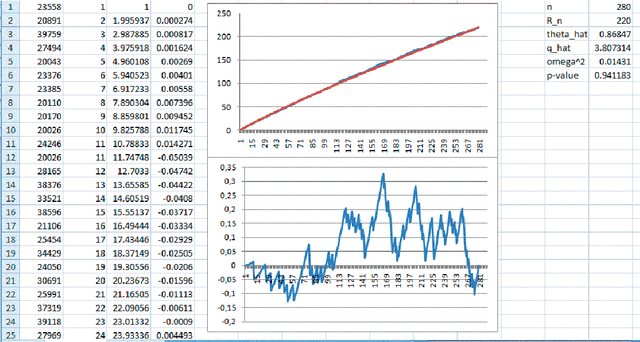
We analyse correspondence of a text to a simple probabilistic model. The model assumes that the words are selected independently from an infinite dictionary. The probability distribution correspond to the Zipf---Mandelbrot law. We count sequentially the numbers of different words in the text and get the process of the numbers of different words. Then we estimate Zipf---Mandelbrot law parameters using the same sequence and construct an estimate of the expectation of the number of different words in the text. Then we subtract the corresponding values of the estimate from the sequence and normalize along the coordinate axes, obtaining a random process on a segment from 0 to 1. We prove that this process (the empirical text bridge) converges weakly in the uniform metric on $C (0,1)$ to a centered Gaussian process with continuous a.s. paths. We develop and implement an algorithm for approximate calculation of eigenvalues of the covariance function of the limit Gaussian process, and then an algorithm for calculating the probability distribution of the integral of the square of this process. We use the algorithm to analyze uniformity of texts in English, French, Russian and Chinese.