 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChain-of-Thought in Large Language Models: Decoding, Projection, and Activation
Dec 05, 2024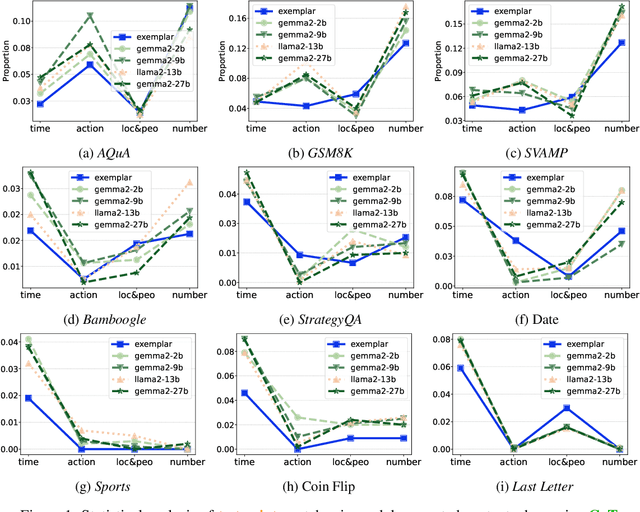

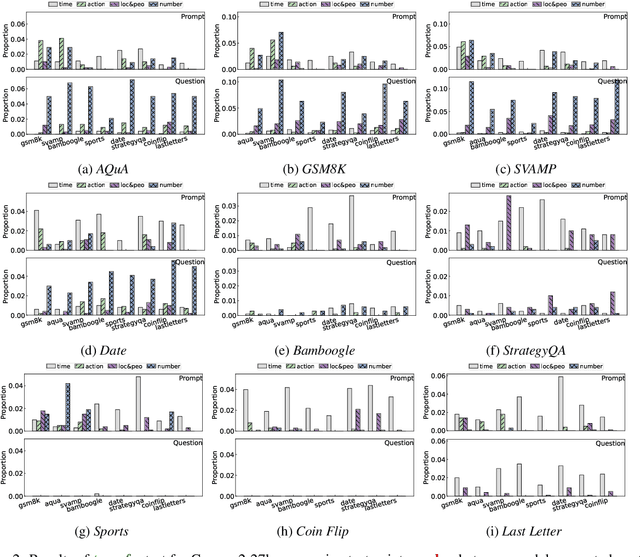
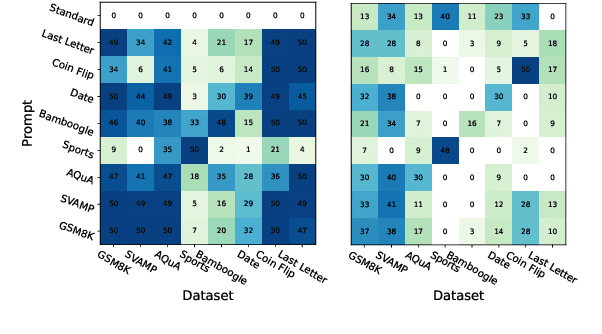
Chain-of-Thought prompting has significantly enhanced the reasoning capabilities of large language models, with numerous studies exploring factors influencing its performance. However, the underlying mechanisms remain poorly understood. To further demystify the operational principles, this work examines three key aspects: decoding, projection, and activation, aiming to elucidate the changes that occur within models when employing Chainof-Thought. Our findings reveal that LLMs effectively imitate exemplar formats while integrating them with their understanding of the question, exhibiting fluctuations in token logits during generation but ultimately producing a more concentrated logits distribution, and activating a broader set of neurons in the final layers, indicating more extensive knowledge retrieval compared to standard prompts. Our code and data will be publicly avialable when the paper is accepted.