 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText Growing on Leaf
Sep 07, 2022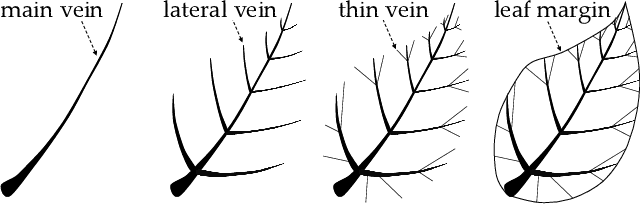
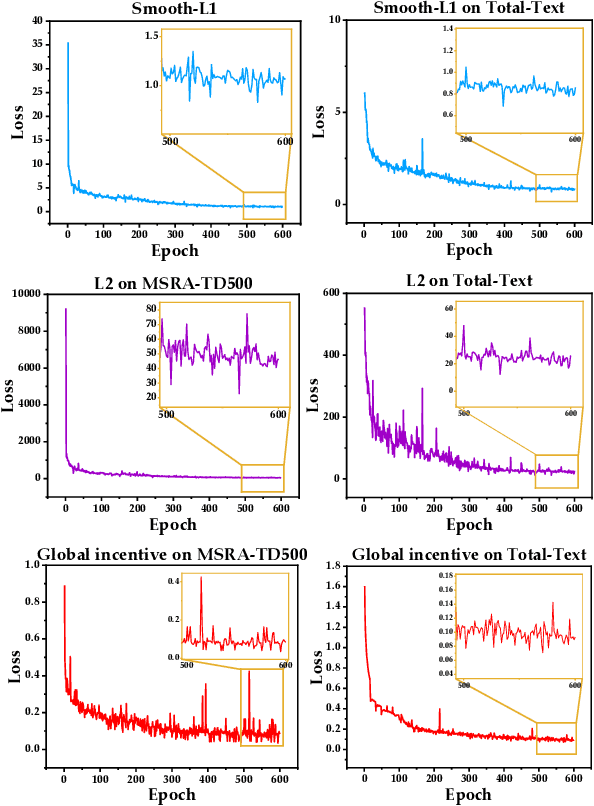


Irregular-shaped texts bring challenges to Scene Text Detection (STD). Although existing contour point sequence-based approaches achieve comparable performances, they fail to cover some highly curved ribbon-like text lines. It leads to limited text fitting ability and STD technique application. Considering the above problem, we combine text geometric characteristics and bionics to design a natural leaf vein-based text representation method (LVT). Concretely, it is found that leaf vein is a generally directed graph, which can easily cover various geometries. Inspired by it, we treat text contour as leaf margin and represent it through main, lateral, and thin veins. We further construct a detection framework based on LVT, namely LeafText. In the text reconstruction stage, LeafText simulates the leaf growth process to rebuild text contour. It grows main vein in Cartesian coordinates to locate text roughly at first. Then, lateral and thin veins are generated along the main vein growth direction in polar coordinates. They are responsible for generating coarse contour and refining it, respectively. Considering the deep dependency of lateral and thin veins on main vein, the Multi-Oriented Smoother (MOS) is proposed to enhance the robustness of main vein to ensure a reliable detection result. Additionally, we propose a global incentive loss to accelerate the predictions of lateral and thin veins. Ablation experiments demonstrate LVT is able to depict arbitrary-shaped texts precisely and verify the effectiveness of MOS and global incentive loss. Comparisons show that LeafText is superior to existing state-of-the-art (SOTA) methods on MSRA-TD500, CTW1500, Total-Text, and ICDAR2015 datasets.
Zoom Text Detector
Sep 07, 2022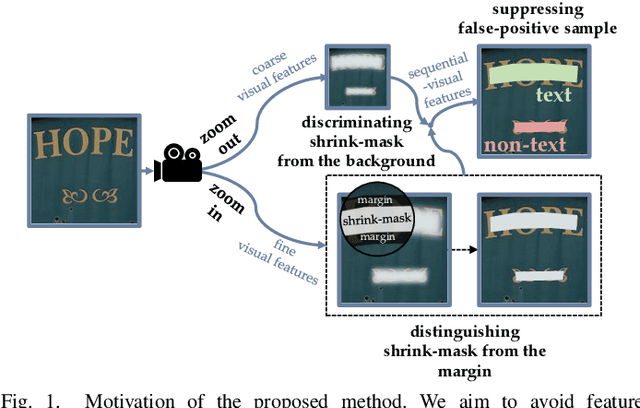



To pursue comprehensive performance, recent text detectors improve detection speed at the expense of accuracy. They adopt shrink-mask based text representation strategies, which leads to a high dependency of detection accuracy on shrink-masks. Unfortunately, three disadvantages cause unreliable shrink-masks. Specifically, these methods try to strengthen the discrimination of shrink-masks from the background by semantic information. However, the feature defocusing phenomenon that coarse layers are optimized by fine-grained objectives limits the extraction of semantic features. Meanwhile, since both shrink-masks and the margins belong to texts, the detail loss phenomenon that the margins are ignored hinders the distinguishment of shrink-masks from the margins, which causes ambiguous shrink-mask edges. Moreover, false-positive samples enjoy similar visual features with shrink-masks. They aggravate the decline of shrink-masks recognition. To avoid the above problems, we propose a Zoom Text Detector (ZTD) inspired by the zoom process of the camera. Specifically, Zoom Out Module (ZOM) is introduced to provide coarse-grained optimization objectives for coarse layers to avoid feature defocusing. Meanwhile, Zoom In Module (ZIM) is presented to enhance the margins recognition to prevent detail loss. Furthermore, Sequential-Visual Discriminator (SVD) is designed to suppress false-positive samples by sequential and visual features. Experiments verify the superior comprehensive performance of ZTD.
Pixel-Level Self-Paced Learning for Super-Resolution
Mar 09, 2020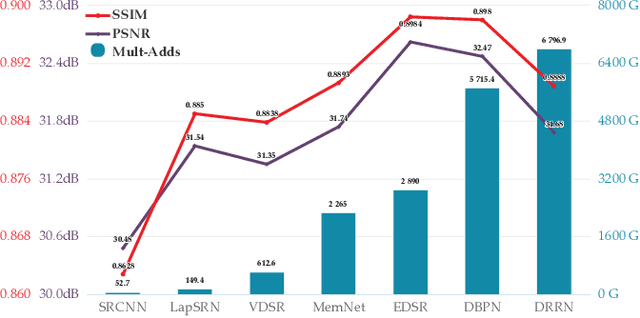

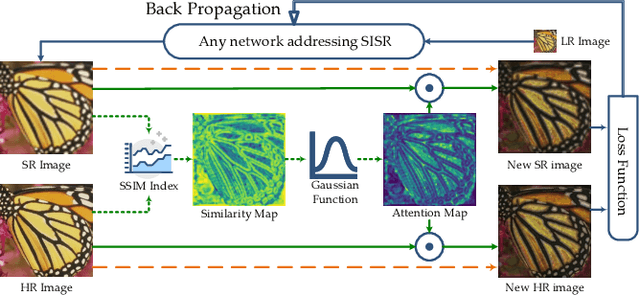
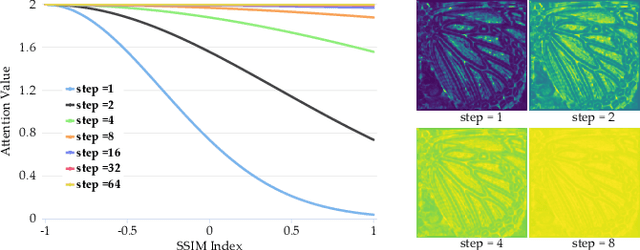
Recently, lots of deep networks are proposed to improve the quality of predicted super-resolution (SR) images, due to its widespread use in several image-based fields. However, with these networks being constructed deeper and deeper, they also cost much longer time for training, which may guide the learners to local optimization. To tackle this problem, this paper designs a training strategy named Pixel-level Self-Paced Learning (PSPL) to accelerate the convergence velocity of SISR models. PSPL imitating self-paced learning gives each pixel in the predicted SR image and its corresponding pixel in ground truth an attention weight, to guide the model to a better region in parameter space. Extensive experiments proved that PSPL could speed up the training of SISR models, and prompt several existing models to obtain new better results. Furthermore, the source code is available at https://github.com/Elin24/PSPL.