 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZoom Text Detector
Paper and Code
Sep 07, 2022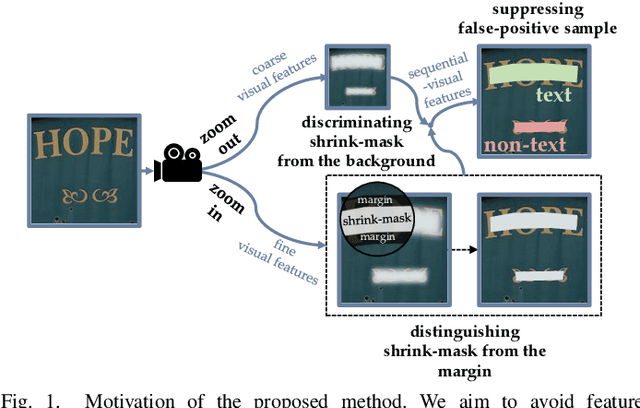



To pursue comprehensive performance, recent text detectors improve detection speed at the expense of accuracy. They adopt shrink-mask based text representation strategies, which leads to a high dependency of detection accuracy on shrink-masks. Unfortunately, three disadvantages cause unreliable shrink-masks. Specifically, these methods try to strengthen the discrimination of shrink-masks from the background by semantic information. However, the feature defocusing phenomenon that coarse layers are optimized by fine-grained objectives limits the extraction of semantic features. Meanwhile, since both shrink-masks and the margins belong to texts, the detail loss phenomenon that the margins are ignored hinders the distinguishment of shrink-masks from the margins, which causes ambiguous shrink-mask edges. Moreover, false-positive samples enjoy similar visual features with shrink-masks. They aggravate the decline of shrink-masks recognition. To avoid the above problems, we propose a Zoom Text Detector (ZTD) inspired by the zoom process of the camera. Specifically, Zoom Out Module (ZOM) is introduced to provide coarse-grained optimization objectives for coarse layers to avoid feature defocusing. Meanwhile, Zoom In Module (ZIM) is presented to enhance the margins recognition to prevent detail loss. Furthermore, Sequential-Visual Discriminator (SVD) is designed to suppress false-positive samples by sequential and visual features. Experiments verify the superior comprehensive performance of ZTD.