 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Customer Feedback for Multi-modal Insight Extraction
Oct 13, 2024Businesses can benefit from customer feedback in different modalities, such as text and images, to enhance their products and services. However, it is difficult to extract actionable and relevant pairs of text segments and images from customer feedback in a single pass. In this paper, we propose a novel multi-modal method that fuses image and text information in a latent space and decodes it to extract the relevant feedback segments using an image-text grounded text decoder. We also introduce a weakly-supervised data generation technique that produces training data for this task. We evaluate our model on unseen data and demonstrate that it can effectively mine actionable insights from multi-modal customer feedback, outperforming the existing baselines by $14$ points in F1 score.
Forecasting directional movements of stock prices for intraday trading using LSTM and random forests
Apr 21, 2020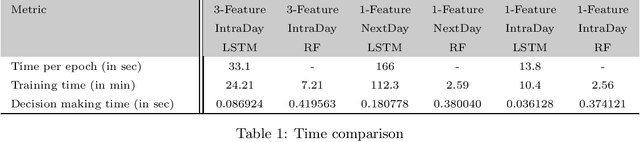

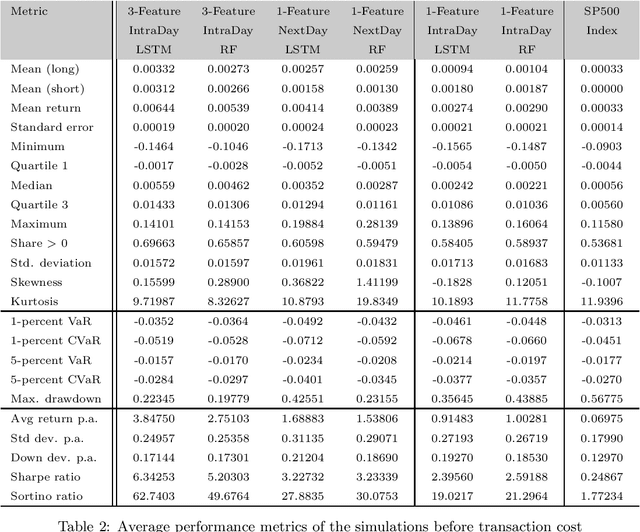
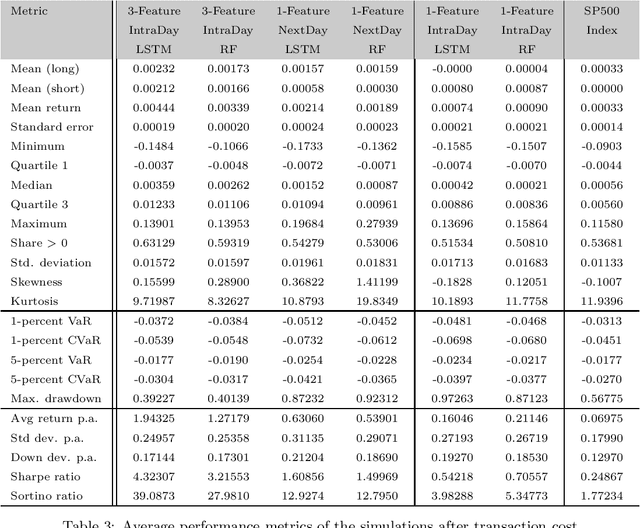
We employ both random forests and LSTM networks (more precisely CuDNNLSTM) as training methodologies to analyze their effectiveness in forecasting out-of-sample directional movements of constituent stocks of the S&P 500 from January 1993 till December 2018 for intraday trading. We introduce a multi-feature setting consisting not only of the returns with respect to the closing prices, but also with respect to the opening prices and intraday returns. As trading strategy, we use Krauss et al. (2017) and Fischer & Krauss (2018) as benchmark and, on each trading day, buy the 10 stocks with the highest probability and sell short the 10 stocks with the lowest probability to outperform the market in terms of intraday returns -- all with equal monetary weight. Our empirical results show that the multi-feature setting provides a daily return, prior to transaction costs, of 0.64% using LSTM networks, and 0.54% using random forests. Hence we outperform the single-feature setting in Fischer & Krauss (2018) and Krauss et al. (2017) consisting only of the daily returns with respect to the closing prices, having corresponding daily returns of 0.41% and of 0.39% with respect to LSTM and random forests, respectively.