 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Hierarchical Clustering
Mar 03, 2023



Deep clustering has been dominated by flat models, which split a dataset into a predefined number of groups. Although recent methods achieve an extremely high similarity with the ground truth on popular benchmarks, the information contained in the flat partition is limited. In this paper, we introduce CoHiClust, a Contrastive Hierarchical Clustering model based on deep neural networks, which can be applied to typical image data. By employing a self-supervised learning approach, CoHiClust distills the base network into a binary tree without access to any labeled data. The hierarchical clustering structure can be used to analyze the relationship between clusters, as well as to measure the similarity between data points. Experiments demonstrate that CoHiClust generates a reasonable structure of clusters, which is consistent with our intuition and image semantics. Moreover, it obtains superior clustering accuracy on most of the image datasets compared to the state-of-the-art flat clustering models.
Prediction of motor insurance claims occurrence as an imbalanced machine learning problem
Apr 12, 2022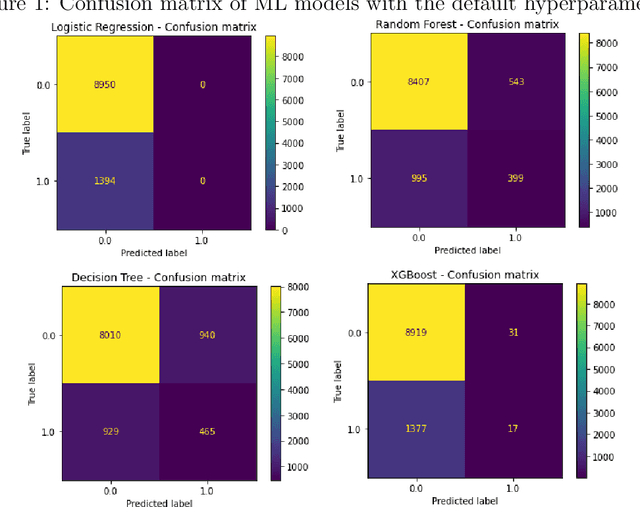

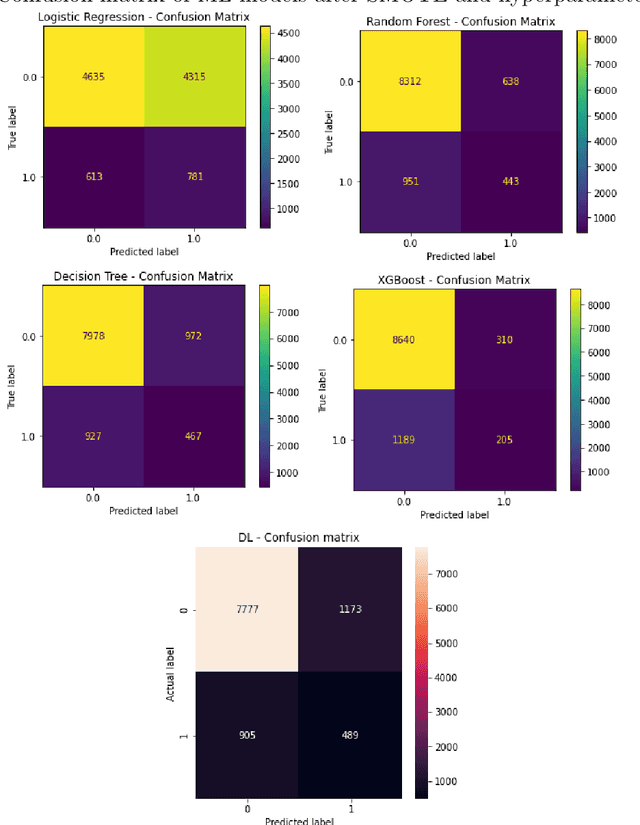
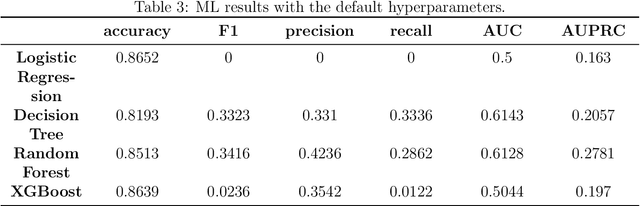
The insurance industry, with its large datasets, is a natural place to use big data solutions. However it must be stressed, that significant number of applications for machine learning in insurance industry, like fraud detection or claim prediction, deals with the problem of machine learning on an imbalanced data set. This is due to the fact that frauds or claims are rare events when compared with the entire population of drivers. The problem of imbalanced learning is often hard to overcome. Therefore, the main goal of this work is to present and apply various methods of dealing with an imbalanced dataset in the context of claim occurrence prediction in car insurance. In addition, the above techniques are used to compare the results of machine learning algorithms in the context of claim occurrence prediction in car insurance. Our study covers the following techniques: logistic-regression, decision tree, random forest, xgBoost, feed-forward network. The problem is the classification one.