 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Nexus Between Retrievability and Query Generation Strategies
Apr 15, 2024Quantifying bias in retrieval functions through document retrievability scores is vital for assessing recall-oriented retrieval systems. However, many studies investigating retrieval model bias lack validation of their query generation methods as accurate representations of retrievability for real users and their queries. This limitation results from the absence of established criteria for query generation in retrievability assessments. Typically, researchers resort to using frequent collocations from document corpora when no query log is available. In this study, we address the issue of reproducibility and seek to validate query generation methods by comparing retrievability scores generated from artificially generated queries to those derived from query logs. Our findings demonstrate a minimal or negligible correlation between retrievability scores from artificial queries and those from query logs. This suggests that artificially generated queries may not accurately reflect retrievability scores as derived from query logs. We further explore alternative query generation techniques, uncovering a variation that exhibits the highest correlation. This alternative approach holds promise for improving reproducibility when query logs are unavailable.
A Comparative Analysis of Retrievability and PageRank Measures
Nov 17, 2023



The accessibility of documents within a collection holds a pivotal role in Information Retrieval, signifying the ease of locating specific content in a collection of documents. This accessibility can be achieved via two distinct avenues. The first is through some retrieval model using a keyword or other feature-based search, and the other is where a document can be navigated using links associated with them, if available. Metrics such as PageRank, Hub, and Authority illuminate the pathways through which documents can be discovered within the network of content while the concept of Retrievability is used to quantify the ease with which a document can be found by a retrieval model. In this paper, we compare these two perspectives, PageRank and retrievability, as they quantify the importance and discoverability of content in a corpus. Through empirical experimentation on benchmark datasets, we demonstrate a subtle similarity between retrievability and PageRank particularly distinguishable for larger datasets.
Findability: A Novel Measure of Information Accessibility
Oct 14, 2023
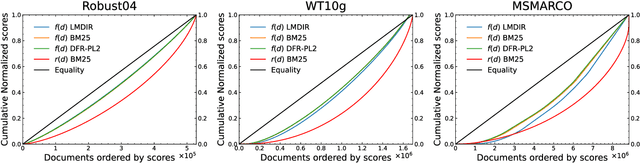
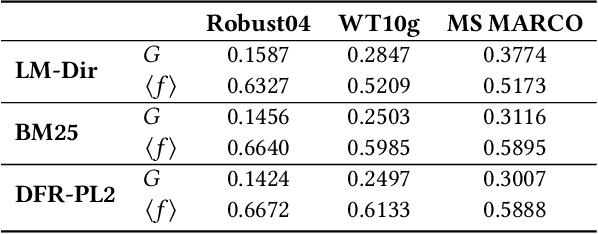

The overwhelming volume of data generated and indexed by search engines poses a significant challenge in retrieving documents from the index efficiently and effectively. Even with a well-crafted query, several relevant documents often get buried among a multitude of competing documents, resulting in reduced accessibility or `findability' of the desired document. Consequently, it is crucial to develop a robust methodology for assessing this dimension of Information Retrieval (IR) system performance. While previous studies have focused on measuring document accessibility disregarding user queries and document relevance, there exists no metric to quantify the findability of a document within a given IR system without resorting to manual labor. This paper aims to address this gap by defining and deriving a metric to evaluate the findability of documents as perceived by end-users. Through experiments, we demonstrate the varying impact of different retrieval models and collections on the findability of documents. Furthermore, we establish the findability measure as an independent metric distinct from retrievability, an accessibility measure introduced in prior literature.