 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAPWise: Evaluating Vision-Language Models for Advanced Map Queries
Aug 30, 2024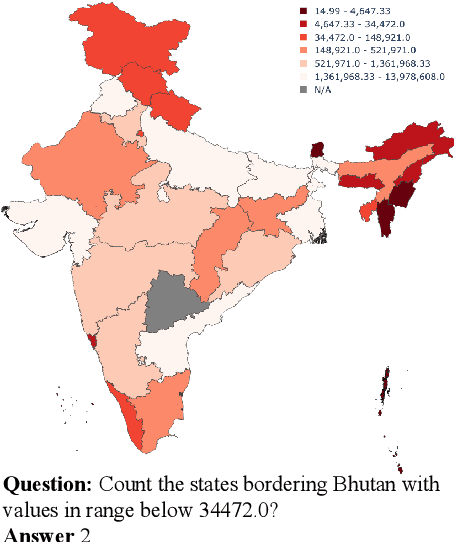

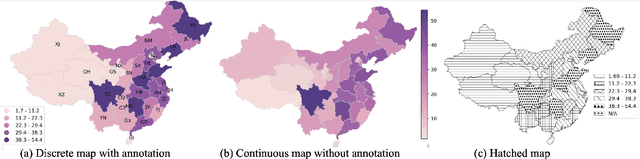

Vision-language models (VLMs) excel at tasks requiring joint understanding of visual and linguistic information. A particularly promising yet under-explored application for these models lies in answering questions based on various kinds of maps. This study investigates the efficacy of VLMs in answering questions based on choropleth maps, which are widely used for data analysis and representation. To facilitate and encourage research in this area, we introduce a novel map-based question-answering benchmark, consisting of maps from three geographical regions (United States, India, China), each containing 1000 questions. Our benchmark incorporates 43 diverse question templates, requiring nuanced understanding of relative spatial relationships, intricate map features, and complex reasoning. It also includes maps with discrete and continuous values, encompassing variations in color-mapping, category ordering, and stylistic patterns, enabling comprehensive analysis. We evaluate the performance of multiple VLMs on this benchmark, highlighting gaps in their abilities and providing insights for improving such models.