 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Linear convergence of Natural Policy Gradient Algorithm
May 04, 2021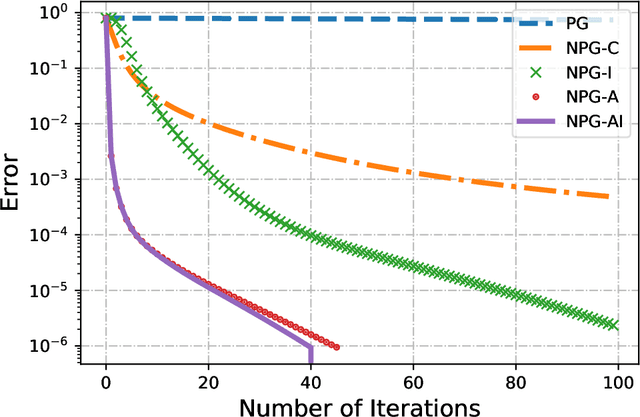
Markov Decision Processes are classically solved using Value Iteration and Policy Iteration algorithms. Recent interest in Reinforcement Learning has motivated the study of methods inspired by optimization, such as gradient ascent. Among these, a popular algorithm is the Natural Policy Gradient, which is a mirror descent variant for MDPs. This algorithm forms the basis of several popular Reinforcement Learning algorithms such as Natural actor-critic, TRPO, PPO, etc, and so is being studied with growing interest. It has been shown that Natural Policy Gradient with constant step size converges with a sublinear rate of O(1/k) to the global optimal. In this paper, we present improved finite time convergence bounds, and show that this algorithm has geometric (also known as linear) asymptotic convergence rate. We further improve this convergence result by introducing a variant of Natural Policy Gradient with adaptive step sizes. Finally, we compare different variants of policy gradient methods experimentally.