 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElastic Weight Consolidation for Full-Parameter Continual Pre-Training of Gemma2
May 09, 2025This technical report describes an experiment on autoregressive pre-training of Gemma2 2 billion parameter large language model (LLM) with 10\% on the Lithuanian language component of CulturaX from the point of view of continual learning. We apply elastic weight consolidation (EWC) to the full set of the model's parameters and investigate language understanding benchmarks, consisting of Arc, Belebele, Gsm8K, Hellaswag, MMLU, TruthfulQA, and Winogrande sets (both in English and Lithuanian versions), and perplexity benchmarks. We empirically demonstrate that EWC regularisation allows us not only to mitigate catastrophic forgetting effects but also that it is potentially beneficial for learning of the new task with LLMs.
Open Llama2 Model for the Lithuanian Language
Aug 23, 2024



In this paper, we propose and describe the first open Llama2 large language models (LLMs) for the Lithuanian language, including an accompanying question/answer (Q/A) dataset and translations of popular LLM benchmarks. We provide a brief review of open regional LLMs and detailed information on the proposed LLMs and their training process. We also conduct an empirical evaluation, comparing the perplexities of the proposed LLMs with those of other modern open LLMs. In addition, benchmarking the proposed LLMs against language understanding tasks reveals that high-quality pretraining datasets may be essential for achieving models that perform efficiently on these benchmarks. The full realisations of the described LLMs are available in the accompanying open repository~\url{https://huggingface.co/neurotechnology}.
DINO Pre-training for Vision-based End-to-end Autonomous Driving
Jul 15, 2024



In this article, we focus on the pre-training of visual autonomous driving agents in the context of imitation learning. Current methods often rely on a classification-based pre-training, which we hypothesise to be holding back from extending capabilities of implicit image understanding. We propose pre-training the visual encoder of a driving agent using the self-distillation with no labels (DINO) method, which relies on a self-supervised learning paradigm.% and is trained on an unrelated task. Our experiments in CARLA environment in accordance with the Leaderboard benchmark reveal that the proposed pre-training is more efficient than classification-based pre-training, and is on par with the recently proposed pre-training based on visual place recognition (VPRPre).
Testing multivariate normality by testing independence
Nov 20, 2023
We propose a simple multivariate normality test based on Kac-Bernstein's characterization, which can be conducted by utilising existing statistical independence tests for sums and differences of data samples. We also perform its empirical investigation, which reveals that for high-dimensional data, the proposed approach may be more efficient than the alternative ones. The accompanying code repository is provided at \url{https://shorturl.at/rtuy5}.
Measuring Statistical Dependencies via Maximum Norm and Characteristic Functions
Aug 16, 2022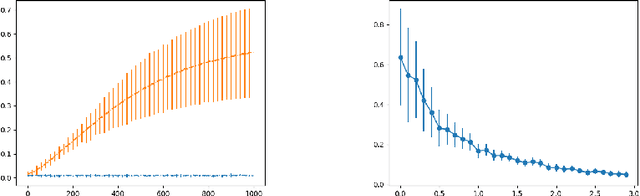
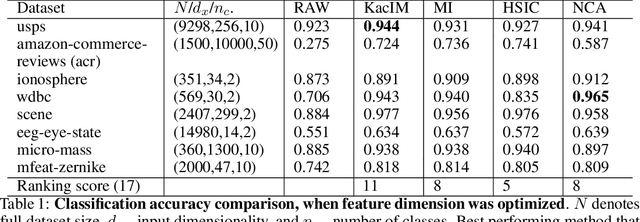
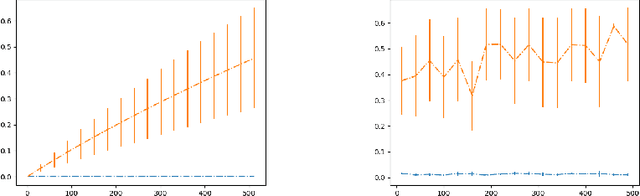
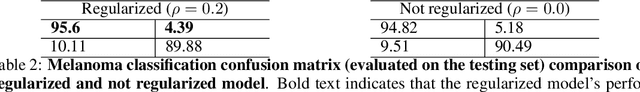
In this paper, we focus on the problem of statistical dependence estimation using characteristic functions. We propose a statistical dependence measure, based on the maximum-norm of the difference between joint and product-marginal characteristic functions. The proposed measure can detect arbitrary statistical dependence between two random vectors of possibly different dimensions, is differentiable, and easily integrable into modern machine learning and deep learning pipelines. We also conduct experiments both with simulated and real data. Our simulations show, that the proposed method can measure statistical dependencies in high-dimensional, non-linear data, and is less affected by the curse of dimensionality, compared to the previous work in this line of research. The experiments with real data demonstrate the potential applicability of our statistical measure for two different empirical inference scenarios, showing statistically significant improvement in the performance characteristics when applied for supervised feature extraction and deep neural network regularization. In addition, we provide a link to the accompanying open-source repository https://bit.ly/3d4ch5I.