 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning Techniques for Pattern Recognition in High-Dimensional Data Mining
Dec 20, 2024This paper proposes a frequent pattern data mining algorithm based on support vector machine (SVM), aiming to solve the performance bottleneck of traditional frequent pattern mining algorithms in high-dimensional and sparse data environments. By converting the frequent pattern mining task into a classification problem, the SVM model is introduced to improve the accuracy and robustness of pattern extraction. In terms of method design, the kernel function is used to map the data to a high-dimensional feature space, so as to construct the optimal classification hyperplane, realize the nonlinear separation of patterns and the accurate mining of frequent items. In the experiment, two public datasets, Retail and Mushroom, were selected to compare and analyze the proposed algorithm with traditional FP-Growth, FP-Tree, decision tree and random forest models. The experimental results show that the algorithm in this paper is significantly better than the traditional model in terms of three key indicators: support, confidence and lift, showing strong pattern recognition ability and rule extraction effect. The study shows that the SVM model has excellent performance advantages in an environment with high data sparsity and a large number of transactions, and can effectively cope with complex pattern mining tasks. At the same time, this paper also points out the potential direction of future research, including the introduction of deep learning and ensemble learning frameworks to further improve the scalability and adaptability of the algorithm. This research not only provides a new idea for frequent pattern mining, but also provides important technical support for solving pattern discovery and association rule mining problems in practical applications.
Reinforcement Learning for Adaptive Resource Scheduling in Complex System Environments
Nov 08, 2024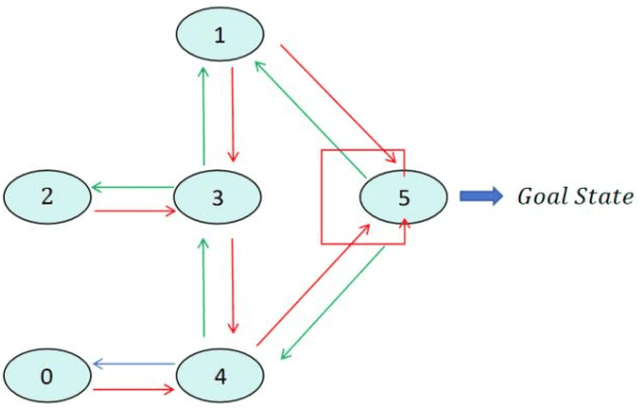
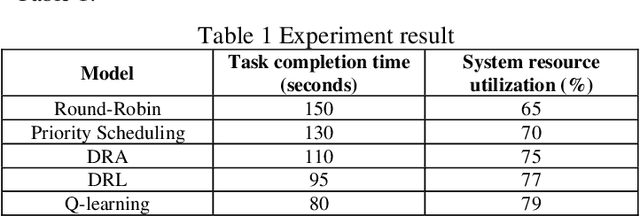
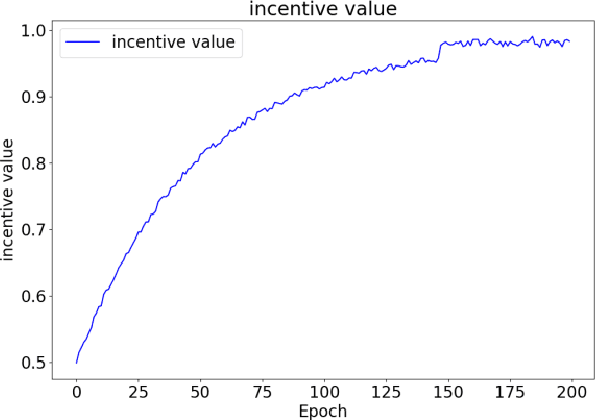

This study presents a novel computer system performance optimization and adaptive workload management scheduling algorithm based on Q-learning. In modern computing environments, characterized by increasing data volumes, task complexity, and dynamic workloads, traditional static scheduling methods such as Round-Robin and Priority Scheduling fail to meet the demands of efficient resource allocation and real-time adaptability. By contrast, Q-learning, a reinforcement learning algorithm, continuously learns from system state changes, enabling dynamic scheduling and resource optimization. Through extensive experiments, the superiority of the proposed approach is demonstrated in both task completion time and resource utilization, outperforming traditional and dynamic resource allocation (DRA) algorithms. These findings are critical as they highlight the potential of intelligent scheduling algorithms based on reinforcement learning to address the growing complexity and unpredictability of computing environments. This research provides a foundation for the integration of AI-driven adaptive scheduling in future large-scale systems, offering a scalable, intelligent solution to enhance system performance, reduce operating costs, and support sustainable energy consumption. The broad applicability of this approach makes it a promising candidate for next-generation computing frameworks, such as edge computing, cloud computing, and the Internet of Things.