 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMansformer: Efficient Transformer of Mixed Attention for Image Deblurring and Beyond
Apr 09, 2024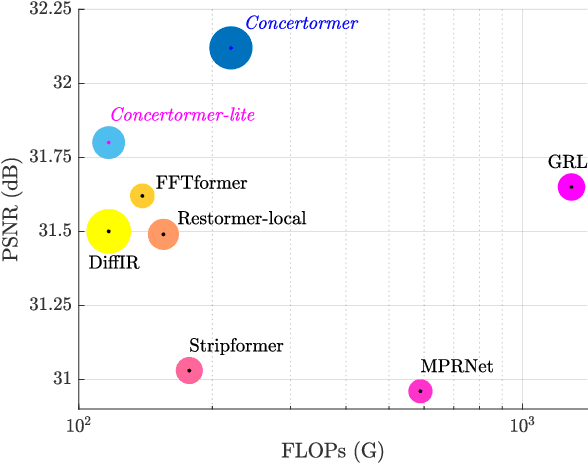
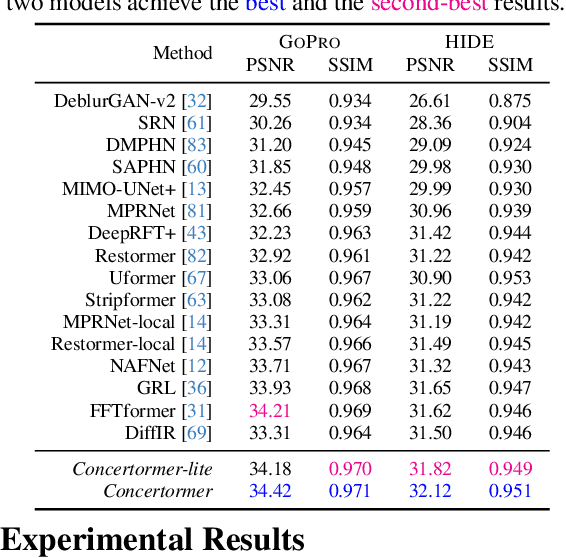
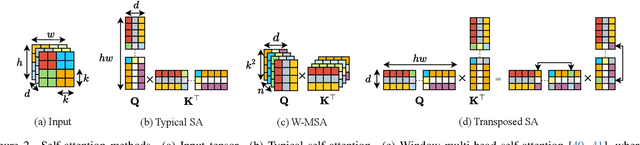
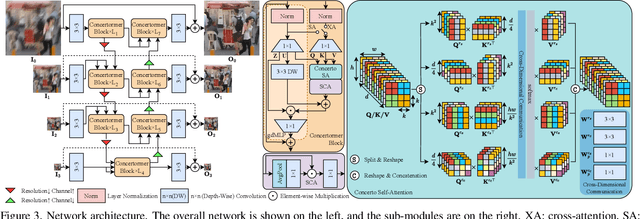
Transformer has made an enormous success in natural language processing and high-level vision over the past few years. However, the complexity of self-attention is quadratic to the image size, which makes it infeasible for high-resolution vision tasks. In this paper, we propose the Mansformer, a Transformer of mixed attention that combines multiple self-attentions, gate, and multi-layer perceptions (MLPs), to explore and employ more possibilities of self-attention. Taking efficiency into account, we design four kinds of self-attention, whose complexities are all linear. By elaborate adjustment of the tensor shapes and dimensions for the dot product, we split the typical self-attention of quadratic complexity into four operations of linear complexity. To adaptively merge these different kinds of self-attention, we take advantage of an architecture similar to Squeeze-and-Excitation Networks. Furthermore, we make it to merge the two-staged Transformer design into one stage by the proposed gated-dconv MLP. Image deblurring is our main target, while extensive quantitative and qualitative evaluations show that this method performs favorably against the state-of-the-art methods far more than simply deblurring. The source codes and trained models will be made available to the public.
Learning Discriminative Shrinkage Deep Networks for Image Deconvolution
Nov 27, 2021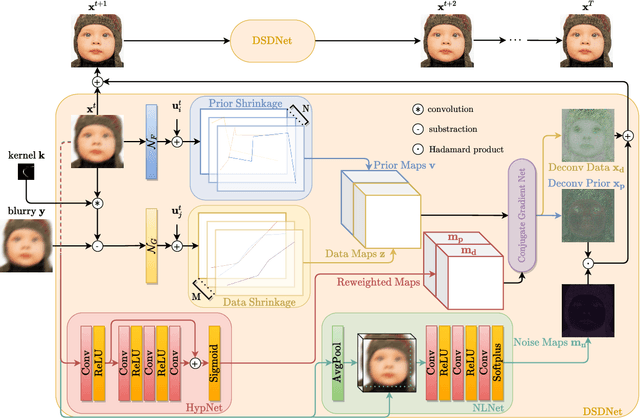
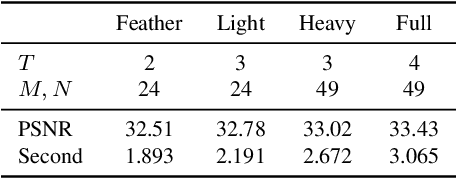
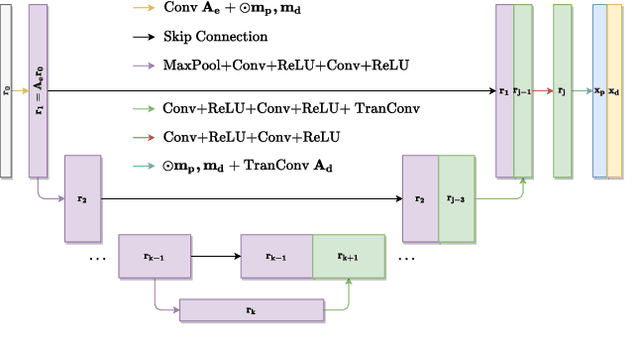
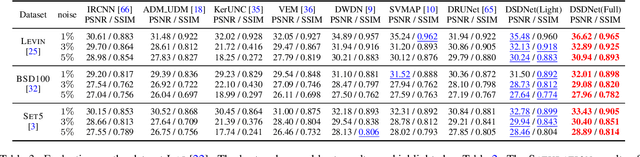
Non-blind deconvolution is an ill-posed problem. Most existing methods usually formulate this problem into a maximum-a-posteriori framework and address it by designing kinds of regularization terms and data terms of the latent clear images. In this paper, we propose an effective non-blind deconvolution approach by learning discriminative shrinkage functions to implicitly model these terms. In contrast to most existing methods that use deep convolutional neural networks (CNNs) or radial basis functions to simply learn the regularization term, we formulate both the data term and regularization term and split the deconvolution model into data-related and regularization-related sub-problems according to the alternating direction method of multipliers. We explore the properties of the Maxout function and develop a deep CNN model with a Maxout layer to learn discriminative shrinkage functions to directly approximate the solutions of these two sub-problems. Moreover, given the fast Fourier transform based image restoration usually leads to ringing artifacts while conjugate gradient-based image restoration is time-consuming, we develop the conjugate gradient network to restore the latent clear images effectively and efficiently. Experimental results show that the proposed method performs favorably against the state-of-the-art ones in terms of efficiency and accuracy.