 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe influence of feature selection methods on accuracy, stability and interpretability of molecular signatures
Jun 23, 2011

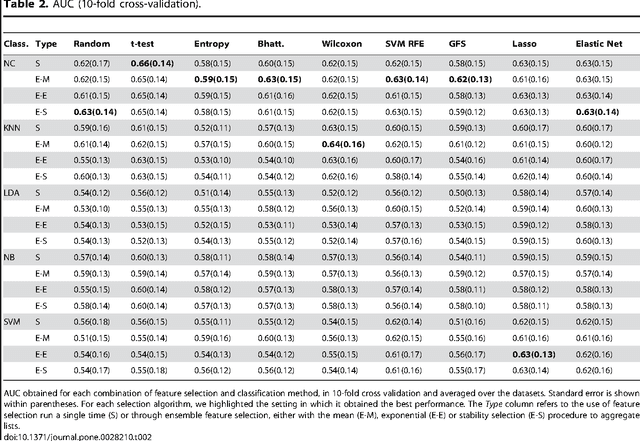

Motivation: Biomarker discovery from high-dimensional data is a crucial problem with enormous applications in biology and medicine. It is also extremely challenging from a statistical viewpoint, but surprisingly few studies have investigated the relative strengths and weaknesses of the plethora of existing feature selection methods. Methods: We compare 32 feature selection methods on 4 public gene expression datasets for breast cancer prognosis, in terms of predictive performance, stability and functional interpretability of the signatures they produce. Results: We observe that the feature selection method has a significant influence on the accuracy, stability and interpretability of signatures. Simple filter methods generally outperform more complex embedded or wrapper methods, and ensemble feature selection has generally no positive effect. Overall a simple Student's t-test seems to provide the best results. Availability: Code and data are publicly available at http://cbio.ensmp.fr/~ahaury/.