 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExponential Convergence of CAVI for Bayesian PCA
May 22, 2025Probabilistic principal component analysis (PCA) and its Bayesian variant (BPCA) are widely used for dimension reduction in machine learning and statistics. The main advantage of probabilistic PCA over the traditional formulation is allowing uncertainty quantification. The parameters of BPCA are typically learned using mean-field variational inference, and in particular, the coordinate ascent variational inference (CAVI) algorithm. So far, the convergence speed of CAVI for BPCA has not been characterized. In our paper, we fill this gap in the literature. Firstly, we prove a precise exponential convergence result in the case where the model uses a single principal component (PC). Interestingly, this result is established through a connection with the classical $\textit{power iteration algorithm}$ and it indicates that traditional PCA is retrieved as points estimates of the BPCA parameters. Secondly, we leverage recent tools to prove exponential convergence of CAVI for the model with any number of PCs, thus leading to a more general result, but one that is of a slightly different flavor. To prove the latter result, we additionally needed to introduce a novel lower bound for the symmetric Kullback--Leibler divergence between two multivariate normal distributions, which, we believe, is of independent interest in information theory.
Improving multiple-try Metropolis with local balancing
Nov 21, 2022Multiple-try Metropolis (MTM) is a popular Markov chain Monte Carlo method with the appealing feature of being amenable to parallel computing. At each iteration, it samples several candidates for the next state of the Markov chain and randomly selects one of them based on a weight function. The canonical weight function is proportional to the target density. We show both theoretically and empirically that this weight function induces pathological behaviours in high dimensions, especially during the convergence phase. We propose to instead use weight functions akin to the locally-balanced proposal distributions of Zanella (2020), thus yielding MTM algorithms that do not exhibit those pathological behaviours. To theoretically analyse these algorithms, we study the high-dimensional performance of ideal schemes that can be think of as MTM algorithms which sample an infinite number of candidates at each iteration, as well as the discrepancy between such schemes and the MTM algorithms which sample a finite number of candidates. Our analysis unveils a strong distinction between the convergence and stationary phases: in the former, local balancing is crucial and effective to achieve fast convergence, while in the latter, the canonical and novel weight functions yield similar performance. Numerical experiments include an application in precision medicine involving a computationally expensive forward model, which makes the use of parallel computing within MTM iterations beneficial.
Optimal scaling of random walk Metropolis algorithms using Bayesian large-sample asymptotics
Apr 27, 2021
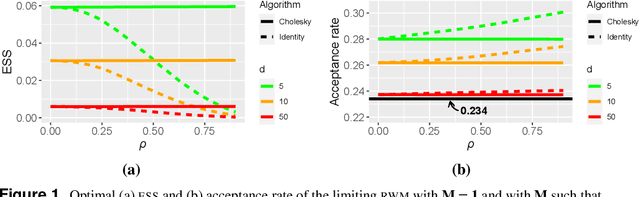
High-dimensional limit theorems have been shown to be useful to derive tuning rules for finding the optimal scaling in random walk Metropolis algorithms. The assumptions under which weak convergence results are proved are however restrictive; the target density is typically assumed to be of a product form. Users may thus doubt the validity of such tuning rules in practical applications. In this paper, we shed some light on optimal scaling problems from a different perspective, namely a large-sample one. This allows to prove weak convergence results under realistic assumptions and to propose novel parameter-dimension-dependent tuning guidelines. The proposed guidelines are consistent with previous ones when the target density is close to having a product form, but significantly different otherwise.