 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeviceScope: An Interactive App to Detect and Localize Appliance Patterns in Electricity Consumption Time Series
Jun 06, 2025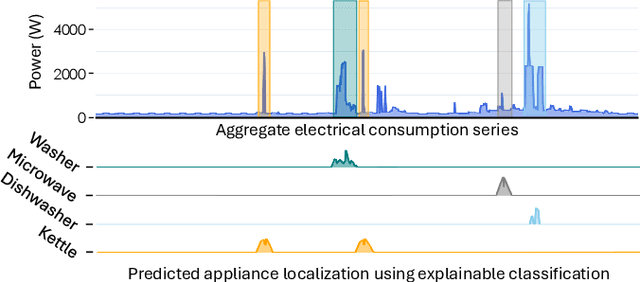
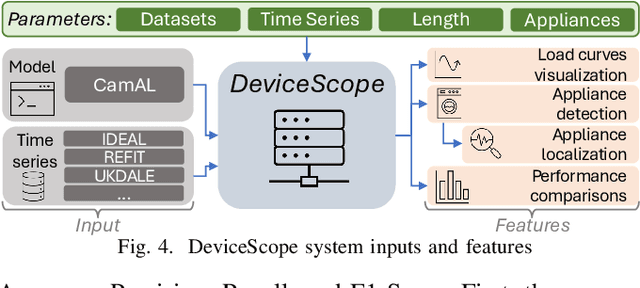
In recent years, electricity suppliers have installed millions of smart meters worldwide to improve the management of the smart grid system. These meters collect a large amount of electrical consumption data to produce valuable information to help consumers reduce their electricity footprint. However, having non-expert users (e.g., consumers or sales advisors) understand these data and derive usage patterns for different appliances has become a significant challenge for electricity suppliers because these data record the aggregated behavior of all appliances. At the same time, ground-truth labels (which could train appliance detection and localization models) are expensive to collect and extremely scarce in practice. This paper introduces DeviceScope, an interactive tool designed to facilitate understanding smart meter data by detecting and localizing individual appliance patterns within a given time period. Our system is based on CamAL (Class Activation Map-based Appliance Localization), a novel weakly supervised approach for appliance localization that only requires the knowledge of the existence of an appliance in a household to be trained. This paper appeared in ICDE 2025.
* 4 pages, 5 figures. This paper appeared in ICDE 2025
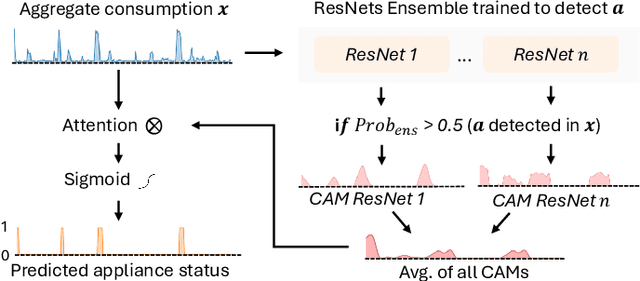
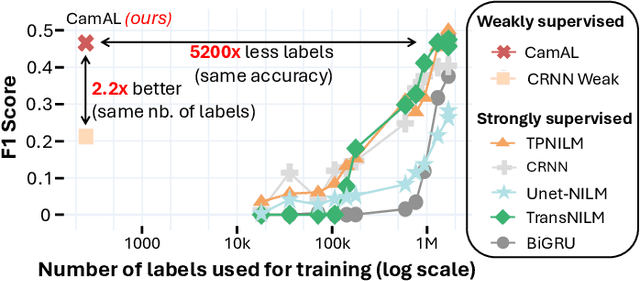
Few Labels are all you need: A Weakly Supervised Framework for Appliance Localization in Smart-Meter Series
Jun 06, 2025Improving smart grid system management is crucial in the fight against climate change, and enabling consumers to play an active role in this effort is a significant challenge for electricity suppliers. In this regard, millions of smart meters have been deployed worldwide in the last decade, recording the main electricity power consumed in individual households. This data produces valuable information that can help them reduce their electricity footprint; nevertheless, the collected signal aggregates the consumption of the different appliances running simultaneously in the house, making it difficult to apprehend. Non-Intrusive Load Monitoring (NILM) refers to the challenge of estimating the power consumption, pattern, or on/off state activation of individual appliances using the main smart meter signal. Recent methods proposed to tackle this task are based on a fully supervised deep-learning approach that requires both the aggregate signal and the ground truth of individual appliance power. However, such labels are expensive to collect and extremely scarce in practice, as they require conducting intrusive surveys in households to monitor each appliance. In this paper, we introduce CamAL, a weakly supervised approach for appliance pattern localization that only requires information on the presence of an appliance in a household to be trained. CamAL merges an ensemble of deep-learning classifiers combined with an explainable classification method to be able to localize appliance patterns. Our experimental evaluation, conducted on 4 real-world datasets, demonstrates that CamAL significantly outperforms existing weakly supervised baselines and that current SotA fully supervised NILM approaches require significantly more labels to reach CamAL performances. The source of our experiments is available at: https://github.com/adrienpetralia/CamAL. This paper appeared in ICDE 2025.
* 12 pages, 10 figures. This paper appeared in IEEE ICDE 2025
NILMFormer: Non-Intrusive Load Monitoring that Accounts for Non-Stationarity
Jun 06, 2025



Millions of smart meters have been deployed worldwide, collecting the total power consumed by individual households. Based on these data, electricity suppliers offer their clients energy monitoring solutions to provide feedback on the consumption of their individual appliances. Historically, such estimates have relied on statistical methods that use coarse-grained total monthly consumption and static customer data, such as appliance ownership. Non-Intrusive Load Monitoring (NILM) is the problem of disaggregating a household's collected total power consumption to retrieve the consumed power for individual appliances. Current state-of-the-art (SotA) solutions for NILM are based on deep-learning (DL) and operate on subsequences of an entire household consumption reading. However, the non-stationary nature of real-world smart meter data leads to a drift in the data distribution within each segmented window, which significantly affects model performance. This paper introduces NILMFormer, a Transformer-based architecture that incorporates a new subsequence stationarization/de-stationarization scheme to mitigate the distribution drift and that uses a novel positional encoding that relies only on the subsequence's timestamp information. Experiments with 4 real-world datasets show that NILMFormer significantly outperforms the SotA approaches. Our solution has been deployed as the backbone algorithm for EDF's (Electricit\'e De France) consumption monitoring service, delivering detailed insights to millions of customers about their individual appliances' power consumption. This paper appeared in KDD 2025.
* 12 pages, 8 figures. This paper appeared in ACM SIGKDD 2025
Appliance Detection Using Very Low-Frequency Smart Meter Time Series
May 21, 2023



In recent years, smart meters have been widely adopted by electricity suppliers to improve the management of the smart grid system. These meters usually collect energy consumption data at a very low frequency (every 30min), enabling utilities to bill customers more accurately. To provide more personalized recommendations, the next step is to detect the appliances owned by customers, which is a challenging problem, due to the very-low meter reading frequency. Even though the appliance detection problem can be cast as a time series classification problem, with many such classifiers having been proposed in the literature, no study has applied and compared them on this specific problem. This paper presents an in-depth evaluation and comparison of state-of-the-art time series classifiers applied to detecting the presence/absence of diverse appliances in very low-frequency smart meter data. We report results with five real datasets. We first study the impact of the detection quality of 13 different appliances using 30min sampled data, and we subsequently propose an analysis of the possible detection performance gain by using a higher meter reading frequency. The results indicate that the performance of current time series classifiers varies significantly. Some of them, namely deep learning-based classifiers, provide promising results in terms of accuracy (especially for certain appliances), even using 30min sampled data, and are scalable to the large smart meter time series collections of energy consumption data currently available to electricity suppliers. Nevertheless, our study shows that more work is needed in this area to further improve the accuracy of the proposed solutions. This paper appeared in ACM e-Energy 2023.
Disk storage management for LHCb based on Data Popularity estimator
Oct 01, 2015



This paper presents an algorithm providing recommendations for optimizing the LHCb data storage. The LHCb data storage system is a hybrid system. All datasets are kept as archives on magnetic tapes. The most popular datasets are kept on disks. The algorithm takes the dataset usage history and metadata (size, type, configuration etc.) to generate a recommendation report. This article presents how we use machine learning algorithms to predict future data popularity. Using these predictions it is possible to estimate which datasets should be removed from disk. We use regression algorithms and time series analysis to find the optimal number of replicas for datasets that are kept on disk. Based on the data popularity and the number of replicas optimization, the algorithm minimizes a loss function to find the optimal data distribution. The loss function represents all requirements for data distribution in the data storage system. We demonstrate how our algorithm helps to save disk space and to reduce waiting times for jobs using this data.