 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Key to State Reduction in Linear Attention: A Rank-based Perspective
Feb 04, 2026Linear attention offers a computationally efficient yet expressive alternative to softmax attention. However, recent empirical results indicate that the state of trained linear attention models often exhibits a low-rank structure, suggesting that these models underexploit their capacity in practice. To illuminate this phenomenon, we provide a theoretical analysis of the role of rank in linear attention, revealing that low effective rank can affect retrieval error by amplifying query noise. In addition to these theoretical insights, we conjecture that the low-rank states can be substantially reduced post-training with only minimal performance degradation, yielding faster and more memory-efficient models. To this end, we propose a novel hardware-aware approach that structurally prunes key and query matrices, reducing the state size while retaining compatibility with existing CUDA kernels. We adapt several existing pruning strategies to fit our framework and, building on our theoretical analysis, propose a novel structured pruning method based on a rank-revealing QR decomposition. Our empirical results, evaluated across models of varying sizes and on various downstream tasks, demonstrate the effectiveness of our state reduction framework. We highlight that our framework enables the removal of 50% of the query and key channels at only a marginal increase in perplexity. The code for this project can be found at https://github.com/camail-official/LinearAttentionPruning.
Entropy Aware Message Passing in Graph Neural Networks
Mar 07, 2024
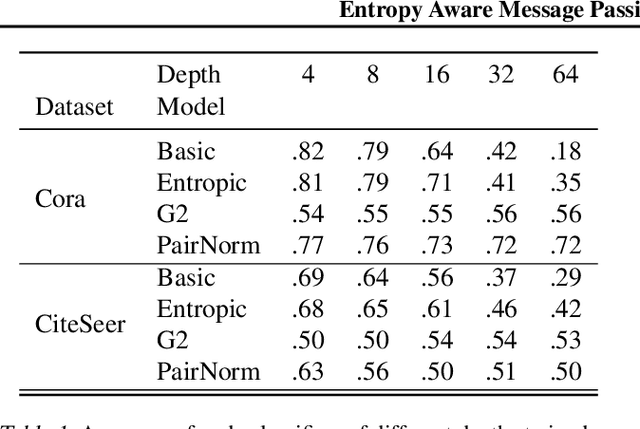
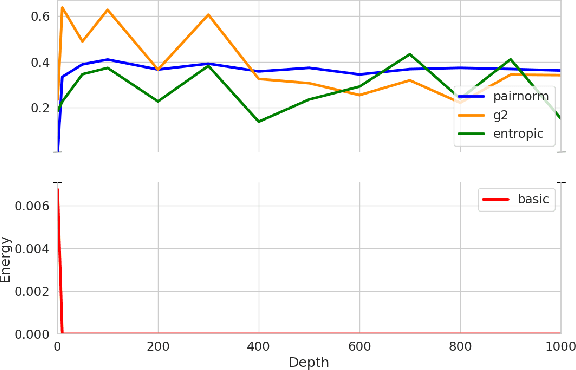
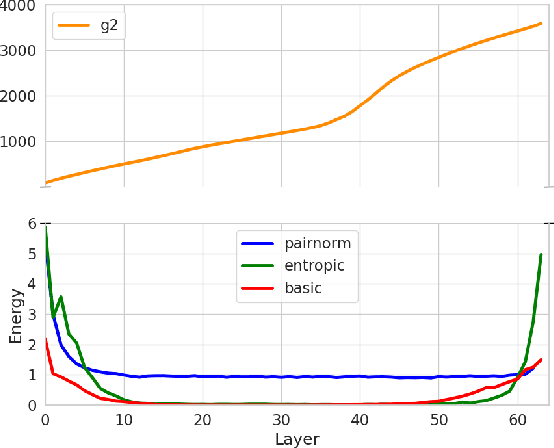
Deep Graph Neural Networks struggle with oversmoothing. This paper introduces a novel, physics-inspired GNN model designed to mitigate this issue. Our approach integrates with existing GNN architectures, introducing an entropy-aware message passing term. This term performs gradient ascent on the entropy during node aggregation, thereby preserving a certain degree of entropy in the embeddings. We conduct a comparative analysis of our model against state-of-the-art GNNs across various common datasets.
Geometric Autoencoders -- What You See is What You Decode
Jun 30, 2023

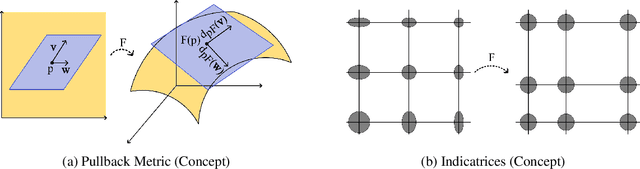

Visualization is a crucial step in exploratory data analysis. One possible approach is to train an autoencoder with low-dimensional latent space. Large network depth and width can help unfolding the data. However, such expressive networks can achieve low reconstruction error even when the latent representation is distorted. To avoid such misleading visualizations, we propose first a differential geometric perspective on the decoder, leading to insightful diagnostics for an embedding's distortion, and second a new regularizer mitigating such distortion. Our ``Geometric Autoencoder'' avoids stretching the embedding spuriously, so that the visualization captures the data structure more faithfully. It also flags areas where little distortion could not be achieved, thus guarding against misinterpretation.