 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransportation Market Rate Forecast Using Signature Transform
Jan 10, 2024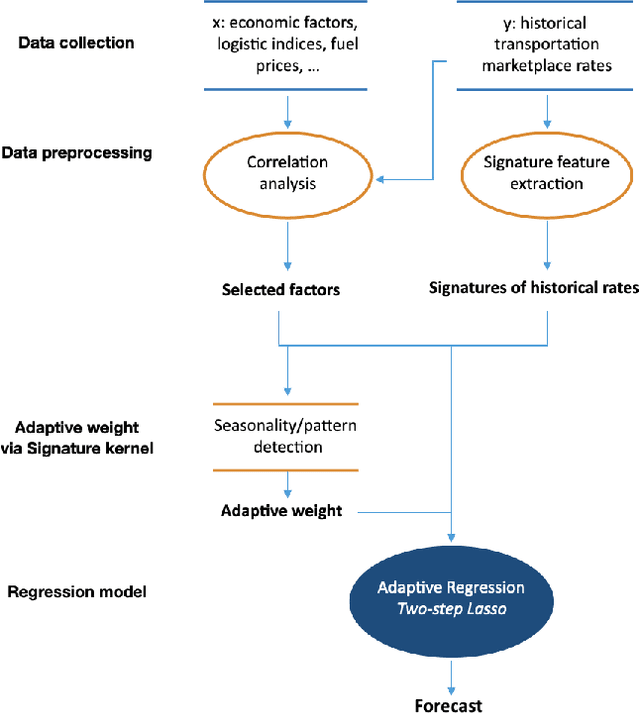
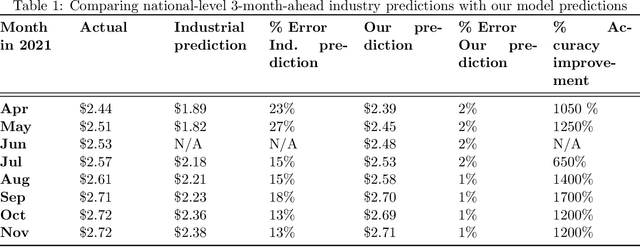
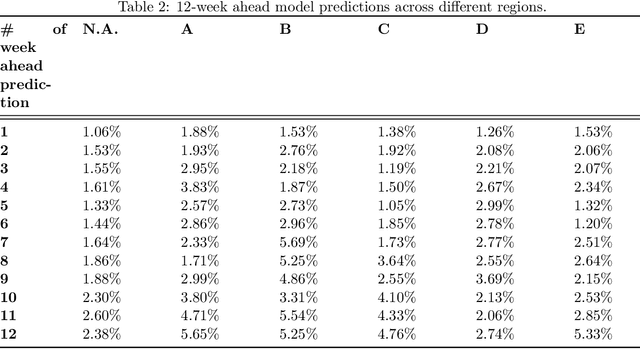
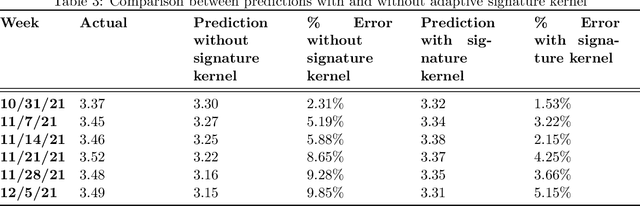
Currently, Amazon relies on third parties for transportation marketplace rate forecasts, despite the poor quality and lack of interpretability of these forecasts. While transportation marketplace rates are typically very challenging to forecast accurately, we have developed a novel signature-based statistical technique to address these challenges and built a predictive and adaptive model to forecast marketplace rates. This novel technique is based on two key properties of the signature transform. The first is its universal nonlinearity which linearizes the feature space and hence translates the forecasting problem into a linear regression analysis; the second is the signature kernel which allows for comparing computationally efficiently similarities between time series data. Combined, these properties allow for efficient feature generation and more precise identification of seasonality and regime switching in the forecasting process. Preliminary result by the model shows that this new technique leads to far superior forecast accuracy versus commercially available industry models with better interpretability, even during the period of Covid-19 and with the sudden onset of the Ukraine war.
Non-Stationary Bandits with Habituation and Recovery Dynamics
Dec 21, 2017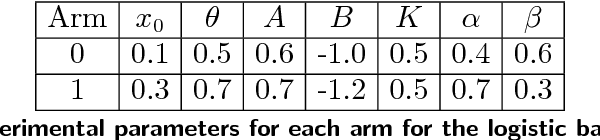
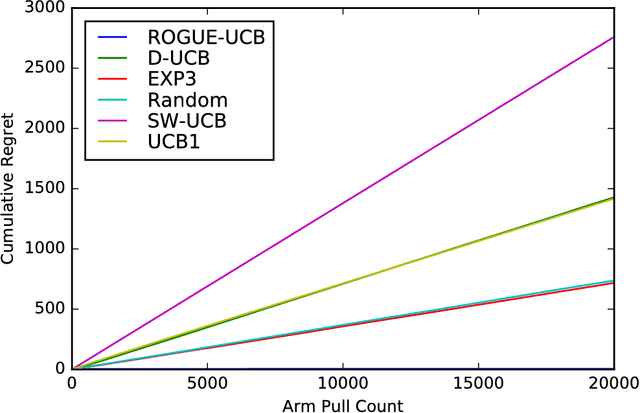
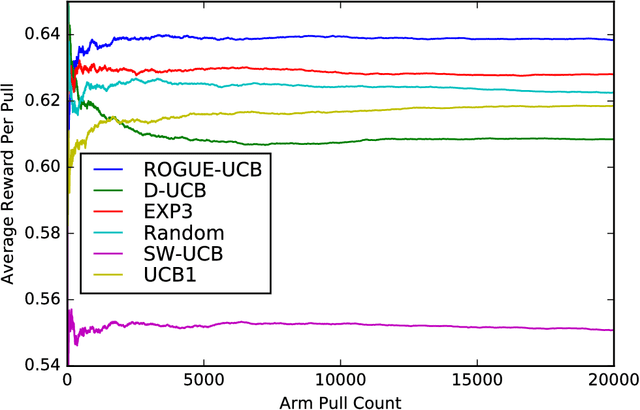

Many settings involve sequential decision-making where a set of actions can be chosen at each time step, each action provides a stochastic reward, and the distribution for the reward of each action is initially unknown. However, frequent selection of a specific action may reduce its expected reward, while abstaining from choosing an action may cause its expected reward to increase. Such non-stationary phenomena are observed in many real world settings such as personalized healthcare-adherence improving interventions and targeted online advertising. Though finding an optimal policy for general models with non-stationarity is PSPACE-complete, we propose and analyze a new class of models called ROGUE (Reducing or Gaining Unknown Efficacy) bandits, which we show in this paper can capture these phenomena and are amenable to the design of effective policies. We first present a consistent maximum likelihood estimator for the parameters of these models. Next, we construct finite sample concentration bounds that lead to an upper confidence bound policy called the ROGUE Upper Confidence Bound (ROGUE-UCB) algorithm. We prove that under proper conditions the ROGUE-UCB algorithm achieves logarithmic in time regret, unlike existing algorithms which result in linear regret. We conclude with a numerical experiment using real data from a personalized healthcare-adherence improving intervention to increase physical activity. In this intervention, the goal is to optimize the selection of messages (e.g., confidence increasing vs. knowledge increasing) to send to each individual each day to increase adherence and physical activity. Our results show that ROGUE-UCB performs better in terms of regret and average reward as compared to state of the art algorithms, and the use of ROGUE-UCB increases daily step counts by roughly 1,000 steps a day (about a half-mile more of walking) as compared to other algorithms.