 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Tale of Two Learning Algorithms: Multiple Stream Random Walk and Asynchronous Gossip
Apr 14, 2025



Although gossip and random walk-based learning algorithms are widely known for decentralized learning, there has been limited theoretical and experimental analysis to understand their relative performance for different graph topologies and data heterogeneity. We first design and analyze a random walk-based learning algorithm with multiple streams (walks), which we name asynchronous "Multi-Walk (MW)". We provide a convergence analysis for MW w.r.t iteration (computation), wall-clock time, and communication. We also present a convergence analysis for "Asynchronous Gossip", noting the lack of a comprehensive analysis of its convergence, along with the computation and communication overhead, in the literature. Our results show that MW has better convergence in terms of iterations as compared to Asynchronous Gossip in graphs with large diameters (e.g., cycles), while its relative performance, as compared to Asynchronous Gossip, depends on the number of walks and the data heterogeneity in graphs with small diameters (e.g., complete graphs). In wall-clock time analysis, we observe a linear speed-up with the number of walks and nodes in MW and Asynchronous Gossip, respectively. Finally, we show that MW outperforms Asynchronous Gossip in communication overhead, except in small-diameter topologies with extreme data heterogeneity. These results highlight the effectiveness of each algorithm in different graph topologies and data heterogeneity. Our codes are available for reproducibility.
Streamlining Image Editing with Layered Diffusion Brushes
May 01, 2024Denoising diffusion models have recently gained prominence as powerful tools for a variety of image generation and manipulation tasks. Building on this, we propose a novel tool for real-time editing of images that provides users with fine-grained region-targeted supervision in addition to existing prompt-based controls. Our novel editing technique, termed Layered Diffusion Brushes, leverages prompt-guided and region-targeted alteration of intermediate denoising steps, enabling precise modifications while maintaining the integrity and context of the input image. We provide an editor based on Layered Diffusion Brushes modifications, which incorporates well-known image editing concepts such as layer masks, visibility toggles, and independent manipulation of layers; regardless of their order. Our system renders a single edit on a 512x512 image within 140 ms using a high-end consumer GPU, enabling real-time feedback and rapid exploration of candidate edits. We validated our method and editing system through a user study involving both natural images (using inversion) and generated images, showcasing its usability and effectiveness compared to existing techniques such as InstructPix2Pix and Stable Diffusion Inpainting for refining images. Our approach demonstrates efficacy across a range of tasks, including object attribute adjustments, error correction, and sequential prompt-based object placement and manipulation, demonstrating its versatility and potential for enhancing creative workflows.
Improved Generalization Bounds for Communication Efficient Federated Learning
Apr 17, 2024



This paper focuses on reducing the communication cost of federated learning by exploring generalization bounds and representation learning. We first characterize a tighter generalization bound for one-round federated learning based on local clients' generalizations and heterogeneity of data distribution (non-iid scenario). We also characterize a generalization bound in R-round federated learning and its relation to the number of local updates (local stochastic gradient descents (SGDs)). Then, based on our generalization bound analysis and our representation learning interpretation of this analysis, we show for the first time that less frequent aggregations, hence more local updates, for the representation extractor (usually corresponds to initial layers) leads to the creation of more generalizable models, particularly for non-iid scenarios. We design a novel Federated Learning with Adaptive Local Steps (FedALS) algorithm based on our generalization bound and representation learning analysis. FedALS employs varying aggregation frequencies for different parts of the model, so reduces the communication cost. The paper is followed with experimental results showing the effectiveness of FedALS.
DIGEST: Fast and Communication Efficient Decentralized Learning with Local Updates
Jul 14, 2023



Two widely considered decentralized learning algorithms are Gossip and random walk-based learning. Gossip algorithms (both synchronous and asynchronous versions) suffer from high communication cost, while random-walk based learning experiences increased convergence time. In this paper, we design a fast and communication-efficient asynchronous decentralized learning mechanism DIGEST by taking advantage of both Gossip and random-walk ideas, and focusing on stochastic gradient descent (SGD). DIGEST is an asynchronous decentralized algorithm building on local-SGD algorithms, which are originally designed for communication efficient centralized learning. We design both single-stream and multi-stream DIGEST, where the communication overhead may increase when the number of streams increases, and there is a convergence and communication overhead trade-off which can be leveraged. We analyze the convergence of single- and multi-stream DIGEST, and prove that both algorithms approach to the optimal solution asymptotically for both iid and non-iid data distributions. We evaluate the performance of single- and multi-stream DIGEST for logistic regression and a deep neural network ResNet20. The simulation results confirm that multi-stream DIGEST has nice convergence properties; i.e., its convergence time is better than or comparable to the baselines in iid setting, and outperforms the baselines in non-iid setting.
Diffusion Brush: A Latent Diffusion Model-based Editing Tool for AI-generated Images
May 31, 2023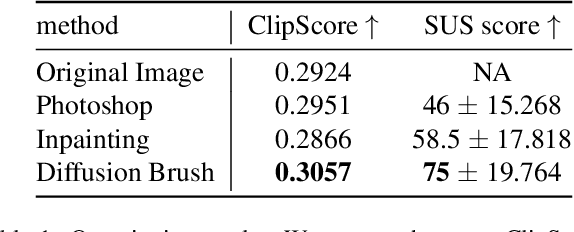
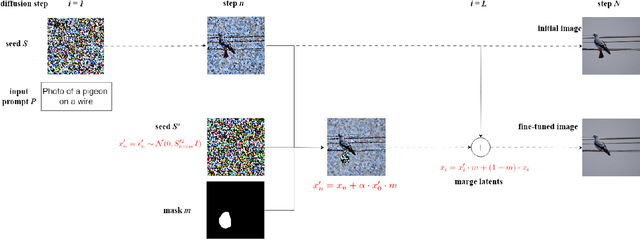


Text-to-image generative models have made remarkable advancements in generating high-quality images. However, generated images often contain undesirable artifacts or other errors due to model limitations. Existing techniques to fine-tune generated images are time-consuming (manual editing), produce poorly-integrated results (inpainting), or result in unexpected changes across the entire image (variation selection and prompt fine-tuning). In this work, we present Diffusion Brush, a Latent Diffusion Model-based (LDM) tool to efficiently fine-tune desired regions within an AI-synthesized image. Our method introduces new random noise patterns at targeted regions during the reverse diffusion process, enabling the model to efficiently make changes to the specified regions while preserving the original context for the rest of the image. We evaluate our method's usability and effectiveness through a user study with artists, comparing our technique against other state-of-the-art image inpainting techniques and editing software for fine-tuning AI-generated imagery.
AutoDepthNet: High Frame Rate Depth Map Reconstruction using Commodity Depth and RGB Cameras
May 24, 2023Depth cameras have found applications in diverse fields, such as computer vision, artificial intelligence, and video gaming. However, the high latency and low frame rate of existing commodity depth cameras impose limitations on their applications. We propose a fast and accurate depth map reconstruction technique to reduce latency and increase the frame rate in depth cameras. Our approach uses only a commodity depth camera and color camera in a hybrid camera setup; our prototype is implemented using a Kinect Azure depth camera at 30 fps and a high-speed RGB iPhone 11 Pro camera captured at 240 fps. The proposed network, AutoDepthNet, is an encoder-decoder model that captures frames from the high-speed RGB camera and combines them with previous depth frames to reconstruct a stream of high frame rate depth maps. On GPU, with a 480 x 270 output resolution, our system achieves an inference time of 8 ms, enabling real-time use at up to 200 fps with parallel processing. AutoDepthNet can estimate depth values with an average RMS error of 0.076, a 44.5% improvement compared to an optical flow-based comparison method. Our method can also improve depth map quality by estimating depth values for missing and invalidated pixels. The proposed method can be easily applied to existing depth cameras and facilitates the use of depth cameras in applications that require high-speed depth estimation. We also showcase the effectiveness of the framework in upsampling different sparse datasets e.g. video object segmentation. As a demonstration of our method, we integrated our framework into existing body tracking systems and demonstrated the robustness of the proposed method in such applications.
OCTID: Optical Coherence Tomography Image Database
Dec 17, 2018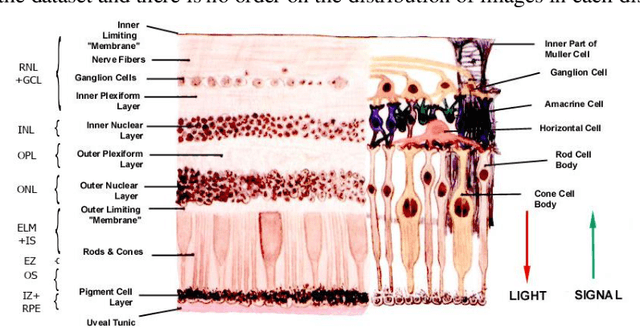
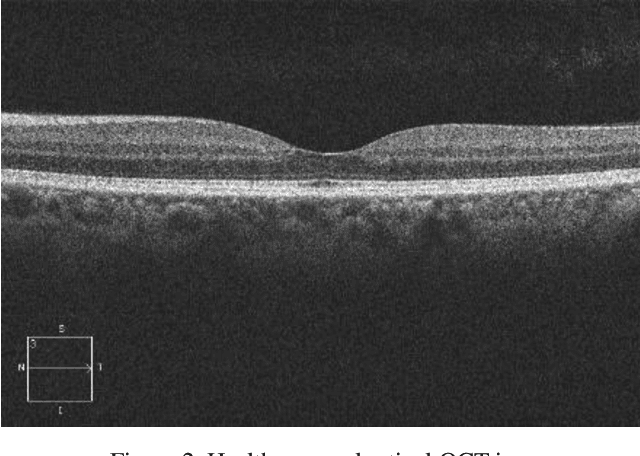
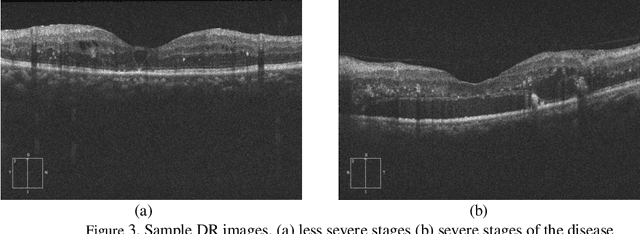
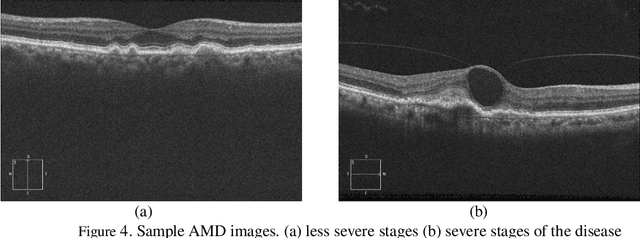
Optical coherence tomography (OCT) is a non-invasive imaging modality which is widely used in clinical ophthalmology. OCT images are capable of visualizing deep retinal layers which is crucial for the early diagnosis of retinal diseases. In this paper, we describe a comprehensive open-access database containing more than 500 high-resolution images categorized into different pathological conditions. The image classes include Normal (NO), Macular Hole (MH), Age-related Macular Degeneration (AMD), Central Serous Retinopathy, and Diabetic Retinopathy (DR). The images were obtained from a raster scan protocol with a 2mm scan length and 512x1024 pixels resolution. We have also included 25 normal OCT images with their corresponding ground truth delineations which can be used for accurate evaluation of OCT image segmentation.