 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreamlining Image Editing with Layered Diffusion Brushes
May 01, 2024Denoising diffusion models have recently gained prominence as powerful tools for a variety of image generation and manipulation tasks. Building on this, we propose a novel tool for real-time editing of images that provides users with fine-grained region-targeted supervision in addition to existing prompt-based controls. Our novel editing technique, termed Layered Diffusion Brushes, leverages prompt-guided and region-targeted alteration of intermediate denoising steps, enabling precise modifications while maintaining the integrity and context of the input image. We provide an editor based on Layered Diffusion Brushes modifications, which incorporates well-known image editing concepts such as layer masks, visibility toggles, and independent manipulation of layers; regardless of their order. Our system renders a single edit on a 512x512 image within 140 ms using a high-end consumer GPU, enabling real-time feedback and rapid exploration of candidate edits. We validated our method and editing system through a user study involving both natural images (using inversion) and generated images, showcasing its usability and effectiveness compared to existing techniques such as InstructPix2Pix and Stable Diffusion Inpainting for refining images. Our approach demonstrates efficacy across a range of tasks, including object attribute adjustments, error correction, and sequential prompt-based object placement and manipulation, demonstrating its versatility and potential for enhancing creative workflows.
Diffusion Brush: A Latent Diffusion Model-based Editing Tool for AI-generated Images
May 31, 2023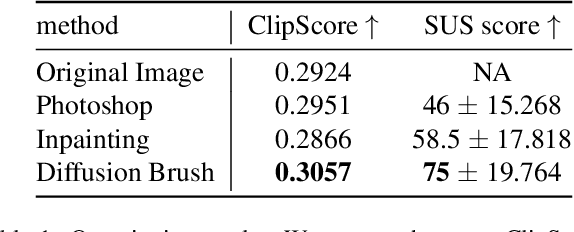
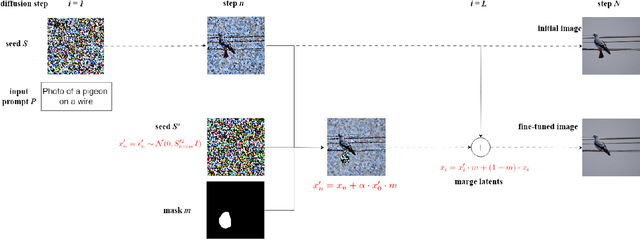


Text-to-image generative models have made remarkable advancements in generating high-quality images. However, generated images often contain undesirable artifacts or other errors due to model limitations. Existing techniques to fine-tune generated images are time-consuming (manual editing), produce poorly-integrated results (inpainting), or result in unexpected changes across the entire image (variation selection and prompt fine-tuning). In this work, we present Diffusion Brush, a Latent Diffusion Model-based (LDM) tool to efficiently fine-tune desired regions within an AI-synthesized image. Our method introduces new random noise patterns at targeted regions during the reverse diffusion process, enabling the model to efficiently make changes to the specified regions while preserving the original context for the rest of the image. We evaluate our method's usability and effectiveness through a user study with artists, comparing our technique against other state-of-the-art image inpainting techniques and editing software for fine-tuning AI-generated imagery.
AutoDepthNet: High Frame Rate Depth Map Reconstruction using Commodity Depth and RGB Cameras
May 24, 2023Depth cameras have found applications in diverse fields, such as computer vision, artificial intelligence, and video gaming. However, the high latency and low frame rate of existing commodity depth cameras impose limitations on their applications. We propose a fast and accurate depth map reconstruction technique to reduce latency and increase the frame rate in depth cameras. Our approach uses only a commodity depth camera and color camera in a hybrid camera setup; our prototype is implemented using a Kinect Azure depth camera at 30 fps and a high-speed RGB iPhone 11 Pro camera captured at 240 fps. The proposed network, AutoDepthNet, is an encoder-decoder model that captures frames from the high-speed RGB camera and combines them with previous depth frames to reconstruct a stream of high frame rate depth maps. On GPU, with a 480 x 270 output resolution, our system achieves an inference time of 8 ms, enabling real-time use at up to 200 fps with parallel processing. AutoDepthNet can estimate depth values with an average RMS error of 0.076, a 44.5% improvement compared to an optical flow-based comparison method. Our method can also improve depth map quality by estimating depth values for missing and invalidated pixels. The proposed method can be easily applied to existing depth cameras and facilitates the use of depth cameras in applications that require high-speed depth estimation. We also showcase the effectiveness of the framework in upsampling different sparse datasets e.g. video object segmentation. As a demonstration of our method, we integrated our framework into existing body tracking systems and demonstrated the robustness of the proposed method in such applications.