 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Ability of Image-Language Explainable Models to Resemble Domain Expertise
Sep 19, 2022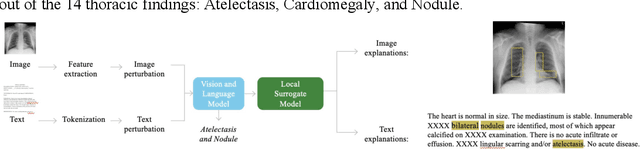

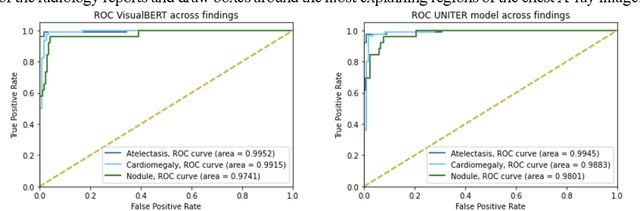

Recent advances in vision and language (V+L) models have a promising impact in the healthcare field. However, such models struggle to explain how and why a particular decision was made. In addition, model transparency and involvement of domain expertise are critical success factors for machine learning models to make an entrance into the field. In this work, we study the use of the local surrogate explainability technique to overcome the problem of black-box deep learning models. We explore the feasibility of resembling domain expertise using the local surrogates in combination with an underlying V+L to generate multi-modal visual and language explanations. We demonstrate that such explanations can serve as helpful feedback in guiding model training for data scientists and machine learning engineers in the field.