 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Linear Feature Space Transformations in Symbolic Regression
Apr 19, 2017



We propose a new type of leaf node for use in Symbolic Regression (SR) that performs linear combinations of feature variables (LCF). These nodes can be handled in three different modes -- an unsynchronized mode, where all LCFs are free to change on their own, a synchronized mode, where LCFs are sorted into groups in which they are forced to be identical throughout the whole individual, and a globally synchronized mode, which is similar to the previous mode but the grouping is done across the whole population. We also present two methods of evolving the weights of the LCFs -- a purely stochastic way via mutation and a gradient-based way based on the backpropagation algorithm known from neural networks -- and also a combination of both. We experimentally evaluate all configurations of LCFs in Multi-Gene Genetic Programming (MGGP), which was chosen as baseline, on a number of benchmarks. According to the results, we identified two configurations which increase the performance of the algorithm.
Symbolic Regression Algorithms with Built-in Linear Regression
Mar 10, 2017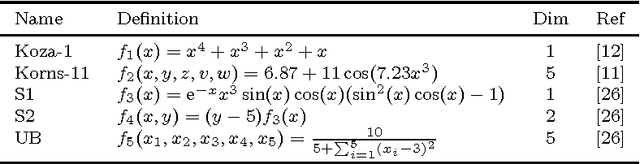
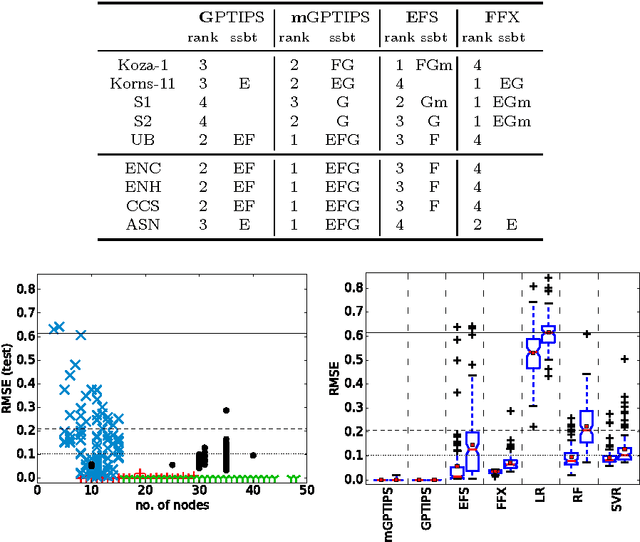

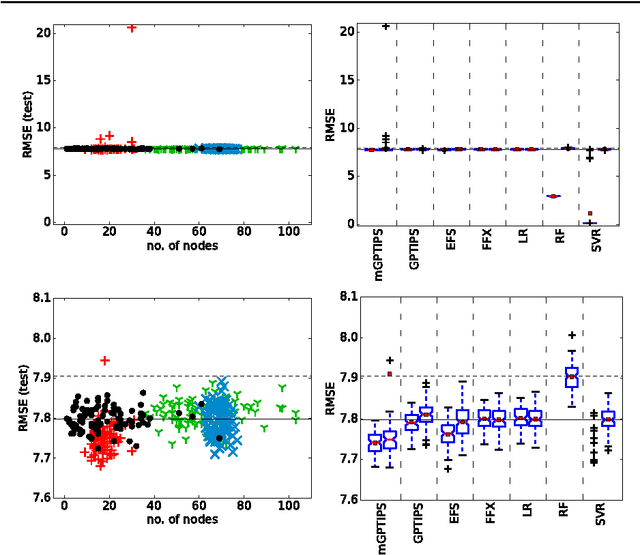
Recently, several algorithms for symbolic regression (SR) emerged which employ a form of multiple linear regression (LR) to produce generalized linear models. The use of LR allows the algorithms to create models with relatively small error right from the beginning of the search; such algorithms are thus claimed to be (sometimes by orders of magnitude) faster than SR algorithms based on vanilla genetic programming. However, a systematic comparison of these algorithms on a common set of problems is still missing. In this paper we conceptually and experimentally compare several representatives of such algorithms (GPTIPS, FFX, and EFS). They are applied as off-the-shelf, ready-to-use techniques, mostly using their default settings. The methods are compared on several synthetic and real-world SR benchmark problems. Their performance is also related to the performance of three conventional machine learning algorithms --- multiple regression, random forests and support vector regression.
Model Selection and Overfitting in Genetic Programming: Empirical Study [Extended Version]
May 04, 2015![Figure 1 for Model Selection and Overfitting in Genetic Programming: Empirical Study [Extended Version]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2F32d62072651fa1c113cc7e7f72cd402da935e30d%2F2-Figure1-1.png&w=640&q=75)
![Figure 2 for Model Selection and Overfitting in Genetic Programming: Empirical Study [Extended Version]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2F32d62072651fa1c113cc7e7f72cd402da935e30d%2F4-Table1-1.png&w=640&q=75)
![Figure 3 for Model Selection and Overfitting in Genetic Programming: Empirical Study [Extended Version]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2F32d62072651fa1c113cc7e7f72cd402da935e30d%2F3-Figure2-1.png&w=640&q=75)
![Figure 4 for Model Selection and Overfitting in Genetic Programming: Empirical Study [Extended Version]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2F32d62072651fa1c113cc7e7f72cd402da935e30d%2F5-Table2-1.png&w=640&q=75)
Genetic Programming has been very successful in solving a large area of problems but its use as a machine learning algorithm has been limited so far. One of the reasons is the problem of overfitting which cannot be solved or suppresed as easily as in more traditional approaches. Another problem, closely related to overfitting, is the selection of the final model from the population. In this article we present our research that addresses both problems: overfitting and model selection. We compare several ways of dealing with ovefitting, based on Random Sampling Technique (RST) and on using a validation set, all with an emphasis on model selection. We subject each approach to a thorough testing on artificial and real--world datasets and compare them with the standard approach, which uses the full training data, as a baseline.