 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding Representative Interpretations on Convolutional Neural Networks
Aug 20, 2021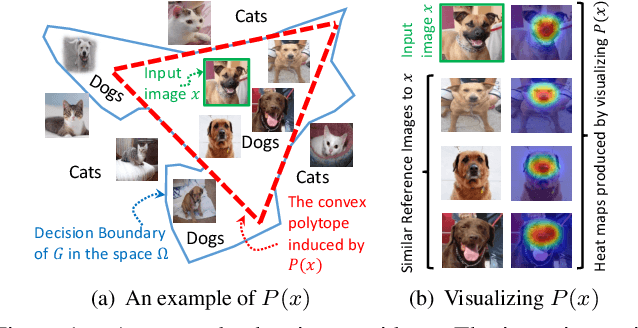

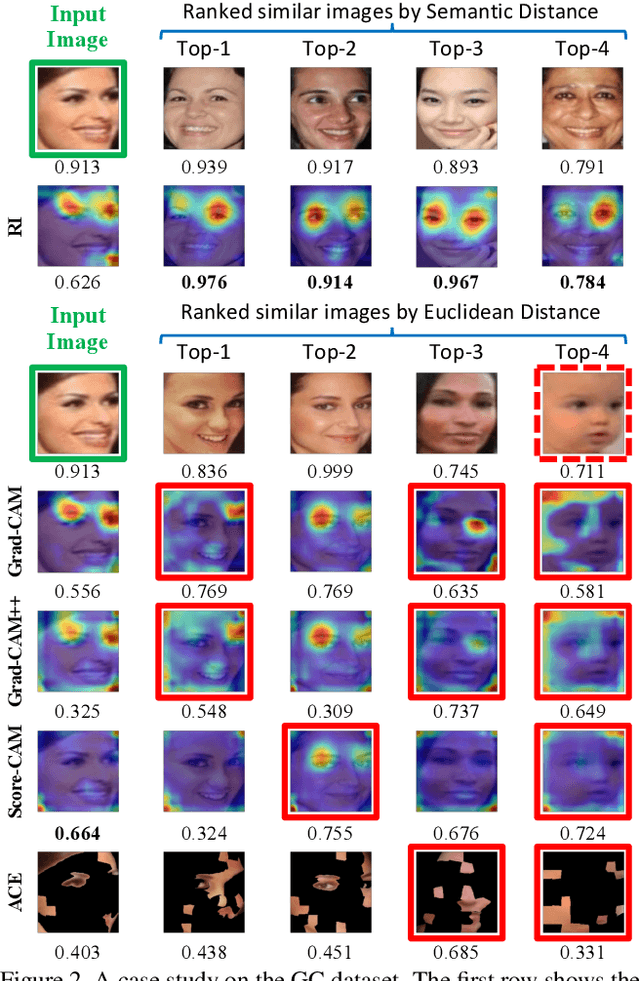

Interpreting the decision logic behind effective deep convolutional neural networks (CNN) on images complements the success of deep learning models. However, the existing methods can only interpret some specific decision logic on individual or a small number of images. To facilitate human understandability and generalization ability, it is important to develop representative interpretations that interpret common decision logics of a CNN on a large group of similar images, which reveal the common semantics data contributes to many closely related predictions. In this paper, we develop a novel unsupervised approach to produce a highly representative interpretation for a large number of similar images. We formulate the problem of finding representative interpretations as a co-clustering problem, and convert it into a submodular cost submodular cover problem based on a sample of the linear decision boundaries of a CNN. We also present a visualization and similarity ranking method. Our extensive experiments demonstrate the excellent performance of our method.
Robust Counterfactual Explanations on Graph Neural Networks
Jul 16, 2021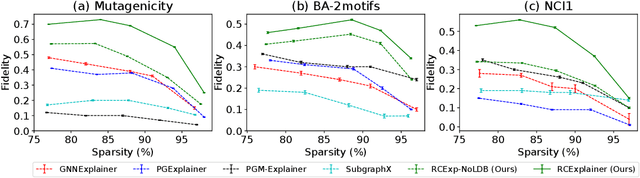

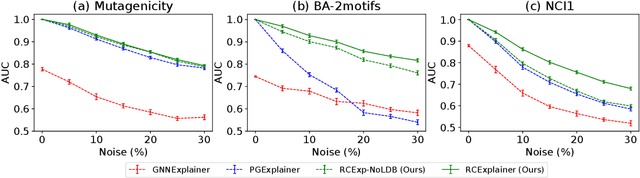
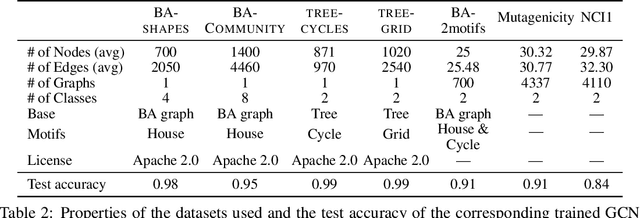
Massive deployment of Graph Neural Networks (GNNs) in high-stake applications generates a strong demand for explanations that are robust to noise and align well with human intuition. Most existing methods generate explanations by identifying a subgraph of an input graph that has a strong correlation with the prediction. These explanations are not robust to noise because independently optimizing the correlation for a single input can easily overfit noise. Moreover, they do not align well with human intuition because removing an identified subgraph from an input graph does not necessarily change the prediction result. In this paper, we propose a novel method to generate robust counterfactual explanations on GNNs by explicitly modelling the common decision logic of GNNs on similar input graphs. Our explanations are naturally robust to noise because they are produced from the common decision boundaries of a GNN that govern the predictions of many similar input graphs. The explanations also align well with human intuition because removing the set of edges identified by an explanation from the input graph changes the prediction significantly. Exhaustive experiments on many public datasets demonstrate the superior performance of our method.