 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Learning for Dynamic Inference
Dec 30, 2022The traditional statistical inference is static, in the sense that the estimate of the quantity of interest does not affect the future evolution of the quantity. In some sequential estimation problems however, the future values of the quantity to be estimated depend on the estimate of its current value. This type of estimation problems has been formulated as the dynamic inference problem. In this work, we formulate the Bayesian learning problem for dynamic inference, where the unknown quantity-generation model is assumed to be randomly drawn according to a random model parameter. We derive the optimal Bayesian learning rules, both offline and online, to minimize the inference loss. Moreover, learning for dynamic inference can serve as a meta problem, such that all familiar machine learning problems, including supervised learning, imitation learning and reinforcement learning, can be cast as its special cases or variants. Gaining a good understanding of this unifying meta problem thus sheds light on a broad spectrum of machine learning problems as well.
Relax but stay in control: from value to algorithms for online Markov decision processes
Aug 31, 2015Online learning algorithms are designed to perform in non-stationary environments, but generally there is no notion of a dynamic state to model constraints on current and future actions as a function of past actions. State-based models are common in stochastic control settings, but commonly used frameworks such as Markov Decision Processes (MDPs) assume a known stationary environment. In recent years, there has been a growing interest in combining the above two frameworks and considering an MDP setting in which the cost function is allowed to change arbitrarily after each time step. However, most of the work in this area has been algorithmic: given a problem, one would develop an algorithm almost from scratch. Moreover, the presence of the state and the assumption of an arbitrarily varying environment complicate both the theoretical analysis and the development of computationally efficient methods. This paper describes a broad extension of the ideas proposed by Rakhlin et al. to give a general framework for deriving algorithms in an MDP setting with arbitrarily changing costs. This framework leads to a unifying view of existing methods and provides a general procedure for constructing new ones. Several new methods are presented, and one of them is shown to have important advantages over a similar method developed from scratch via an online version of approximate dynamic programming.
Online Markov decision processes with Kullback-Leibler control cost
Jan 14, 2014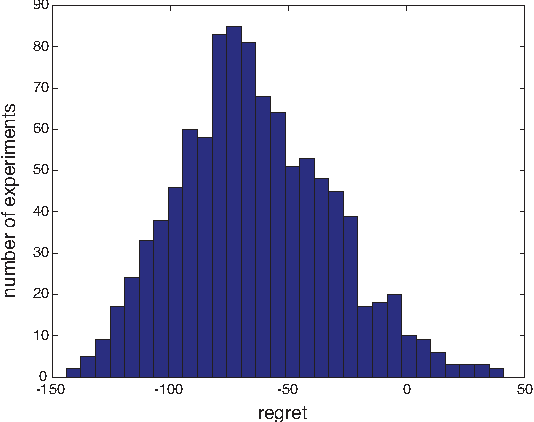
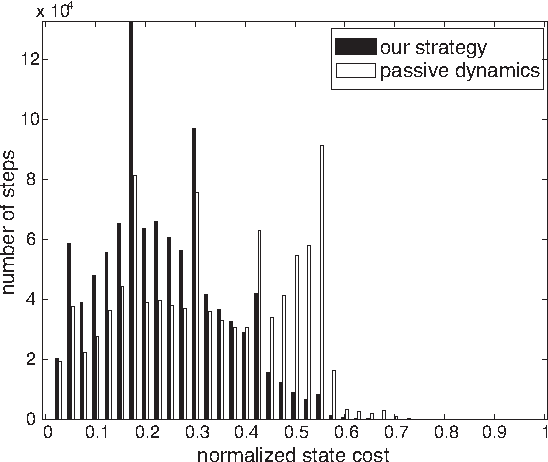
This paper considers an online (real-time) control problem that involves an agent performing a discrete-time random walk over a finite state space. The agent's action at each time step is to specify the probability distribution for the next state given the current state. Following the set-up of Todorov, the state-action cost at each time step is a sum of a state cost and a control cost given by the Kullback-Leibler (KL) divergence between the agent's next-state distribution and that determined by some fixed passive dynamics. The online aspect of the problem is due to the fact that the state cost functions are generated by a dynamic environment, and the agent learns the current state cost only after selecting an action. An explicit construction of a computationally efficient strategy with small regret (i.e., expected difference between its actual total cost and the smallest cost attainable using noncausal knowledge of the state costs) under mild regularity conditions is presented, along with a demonstration of the performance of the proposed strategy on a simulated target tracking problem. A number of new results on Markov decision processes with KL control cost are also obtained.