 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQualitative Evaluation of LLM-Designed GUI
Jan 30, 2026As generative artificial intelligence advances, Large Language Models (LLMs) are being explored for automated graphical user interface (GUI) design. This study investigates the usability and adaptability of LLM-generated interfaces by analysing their ability to meet diverse user needs. The experiments included utilization of three state-of-the-art models from January 2025 (OpenAI GPT o3-mini-high, DeepSeek R1, and Anthropic Claude 3.5 Sonnet) generating mockups for three interface types: a chat system, a technical team panel, and a manager dashboard. Expert evaluations revealed that while LLMs are effective at creating structured layouts, they face challenges in meeting accessibility standards and providing interactive functionality. Further testing showed that LLMs could partially tailor interfaces for different user personas but lacked deeper contextual understanding. The results suggest that while LLMs are promising tools for early-stage UI prototyping, human intervention remains critical to ensure usability, accessibility, and user satisfaction.
Random Similarity Forests
Apr 11, 2022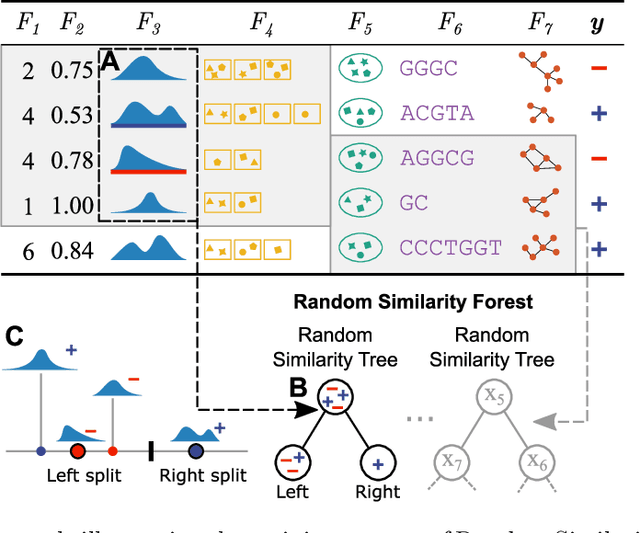
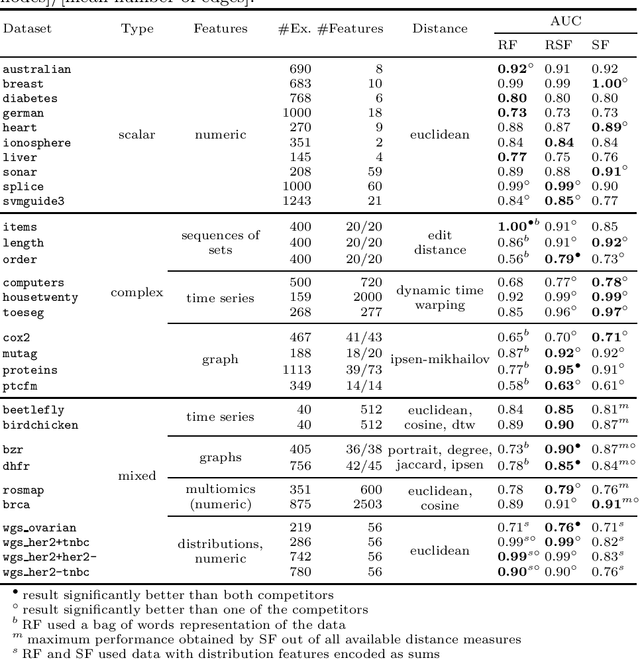
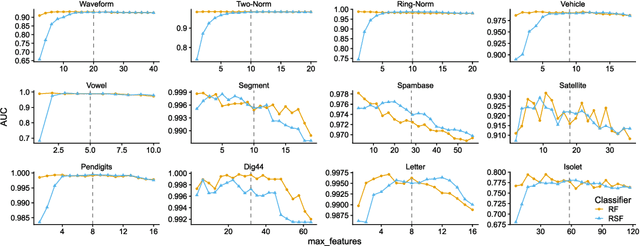
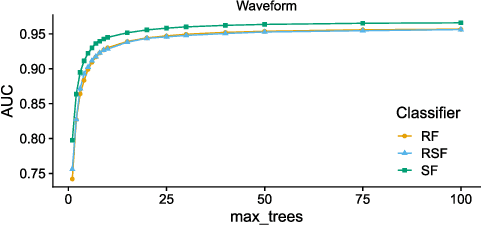
The wealth of data being gathered about humans and their surroundings drives new machine learning applications in various fields. Consequently, more and more often, classifiers are trained using not only numerical data but also complex data objects. For example, multi-omics analyses attempt to combine numerical descriptions with distributions, time series data, discrete sequences, and graphs. Such integration of data from different domains requires either omitting some of the data, creating separate models for different formats, or simplifying some of the data to adhere to a shared scale and format, all of which can hinder predictive performance. In this paper, we propose a classification method capable of handling datasets with features of arbitrary data types while retaining each feature's characteristic. The proposed algorithm, called Random Similarity Forest, uses multiple domain-specific distance measures to combine the predictive performance of Random Forests with the flexibility of Similarity Forests. We show that Random Similarity Forests are on par with Random Forests on numerical data and outperform them on datasets from complex or mixed data domains. Our results highlight the applicability of Random Similarity Forests to noisy, multi-source datasets that are becoming ubiquitous in high-impact life science projects.