 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWarCov -- Large multilabel and multimodal dataset from social platform
Jun 10, 2024



In the classification tasks, from raw data acquisition to the curation of a dataset suitable for use in evaluating machine learning models, a series of steps - often associated with high costs - are necessary. In the case of Natural Language Processing, initial cleaning and conversion can be performed automatically, but obtaining labels still requires the rationalized input of human experts. As a result, even though many articles often state that "the world is filled with data", data scientists suffer from its shortage. It is crucial in the case of natural language applications, which is constantly evolving and must adapt to new concepts or events. For example, the topic of the COVID-19 pandemic and the vocabulary related to it would have been mostly unrecognizable before 2019. For this reason, creating new datasets, also in languages other than English, is still essential. This work presents a collection of 3~187~105 posts in Polish about the pandemic and the war in Ukraine published on popular social media platforms in 2022. The collection includes not only preprocessed texts but also images so it can be used also for multimodal recognition tasks. The labels define posts' topics and were created using hashtags accompanying the posts. The work presents the process of curating a dataset from acquisition to sample pattern recognition experiments.
Taking Class Imbalance Into Account in Open Set Recognition Evaluation
Feb 09, 2024In recent years Deep Neural Network-based systems are not only increasing in popularity but also receive growing user trust. However, due to the closed-world assumption of such systems, they cannot recognize samples from unknown classes and often induce an incorrect label with high confidence. Presented work looks at the evaluation of methods for Open Set Recognition, focusing on the impact of class imbalance, especially in the dichotomy between known and unknown samples. As an outcome of problem analysis, we present a set of guidelines for evaluation of methods in this field.
torchosr -- a PyTorch extension package for Open Set Recognition models evaluation in Python
May 16, 2023The article presents the torchosr package - a Python package compatible with PyTorch library - offering tools and methods dedicated to Open Set Recognition in Deep Neural Networks. The package offers two state-of-the-art methods in the field, a set of functions for handling base sets and generation of derived sets for the Open Set Recognition task (where some classes are considered unknown and used only in the testing process) and additional tools to handle datasets and methods. The main goal of the package proposal is to simplify and promote the correct experimental evaluation, where experiments are carried out on a large number of derivative sets with various Openness and class-to-category assignments. The authors hope that state-of-the-art methods available in the package will become a source of a correct and open-source implementation of the relevant solutions in the domain.
problexity -- an open-source Python library for binary classification problem complexity assessment
Jul 14, 2022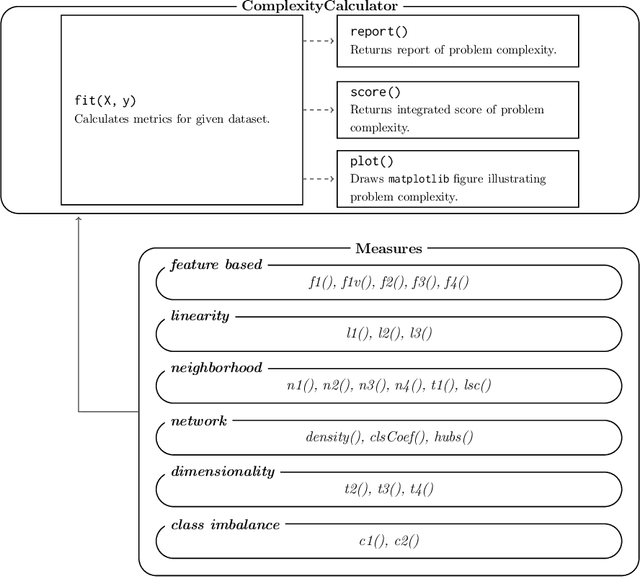
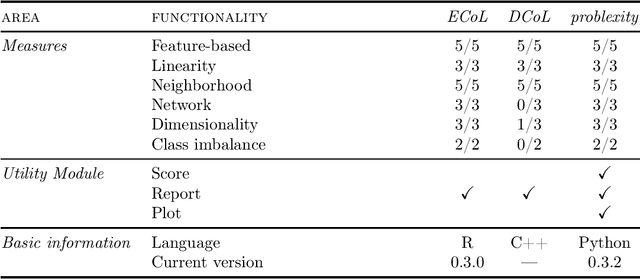
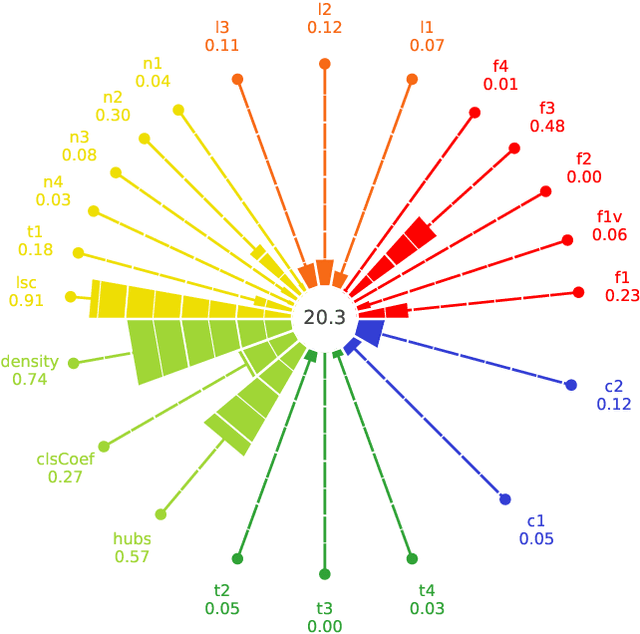

The classification problem's complexity assessment is an essential element of many topics in the supervised learning domain. It plays a significant role in meta-learning -- becoming the basis for determining meta-attributes or multi-criteria optimization -- allowing the evaluation of the training set resampling without needing to rebuild the recognition model. The tools currently available for the academic community, which would enable the calculation of problem complexity measures, are available only as libraries of the C++ and R languages. This paper describes the software module that allows for the estimation of 22 complexity measures for the Python language -- compatible with the scikit-learn programming interface -- allowing for the implementation of research using them in the most popular programming environment of the machine learning community.
Advanced Machine Learning Techniques for Fake News (Online Disinformation) Detection: A Systematic Mapping Study
Dec 28, 2020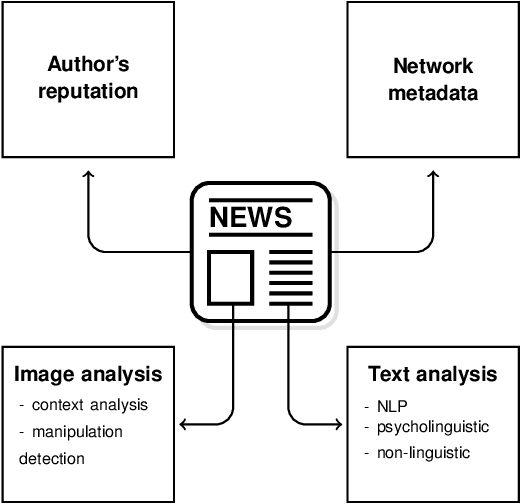
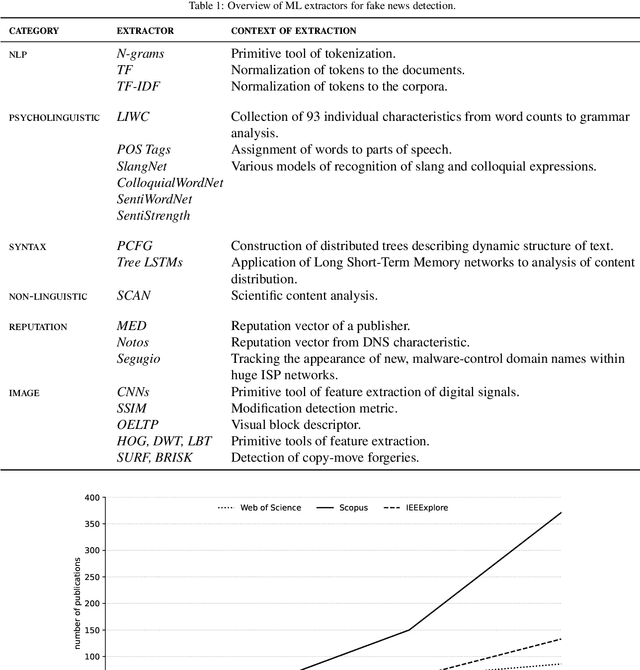


Fake news has now grown into a big problem for societies and also a major challenge for people fighting disinformation. This phenomenon plagues democratic elections, reputations of individual persons or organizations, and has negatively impacted citizens, (e.g., during the COVID-19 pandemic in the US or Brazil). Hence, developing effective tools to fight this phenomenon by employing advanced Machine Learning (ML) methods poses a significant challenge. The following paper displays the present body of knowledge on the application of such intelligent tools in the fight against disinformation. It starts by showing the historical perspective and the current role of fake news in the information war. Proposed solutions based solely on the work of experts are analysed and the most important directions of the application of intelligent systems in the detection of misinformation sources are pointed out. Additionally, the paper presents some useful resources (mainly datasets useful when assessing ML solutions for fake news detection) and provides a short overview of the most important R&D projects related to this subject. The main purpose of this work is to analyse the current state of knowledge in detecting fake news; on the one hand to show possible solutions, and on the other hand to identify the main challenges and methodological gaps to motivate future research.