 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Explanations of Neural Networks Using Pruned Layer-Wise Relevance Propagation
Apr 22, 2024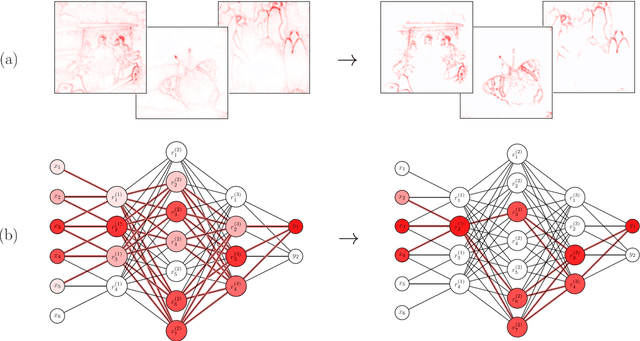
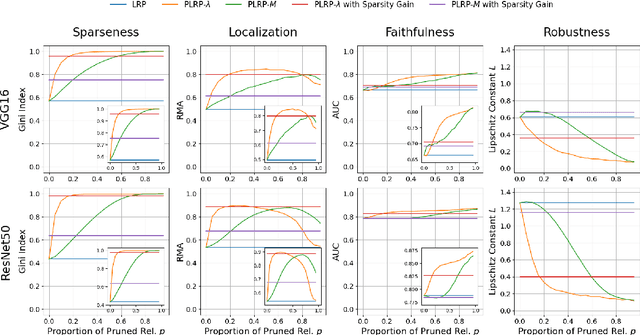
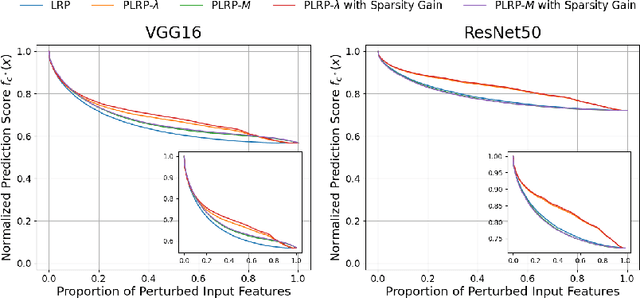

Explainability is a key component in many applications involving deep neural networks (DNNs). However, current explanation methods for DNNs commonly leave it to the human observer to distinguish relevant explanations from spurious noise. This is not feasible anymore when going from easily human-accessible data such as images to more complex data such as genome sequences. To facilitate the accessibility of DNN outputs from such complex data and to increase explainability, we present a modification of the widely used explanation method layer-wise relevance propagation. Our approach enforces sparsity directly by pruning the relevance propagation for the different layers. Thereby, we achieve sparser relevance attributions for the input features as well as for the intermediate layers. As the relevance propagation is input-specific, we aim to prune the relevance propagation rather than the underlying model architecture. This allows to prune different neurons for different inputs and hence, might be more appropriate to the local nature of explanation methods. To demonstrate the efficacy of our method, we evaluate it on two types of data, images and genomic sequences. We show that our modification indeed leads to noise reduction and concentrates relevance on the most important features compared to the baseline.