 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetect and Classify -- Joint Span Detection and Classification for Health Outcomes
Apr 15, 2021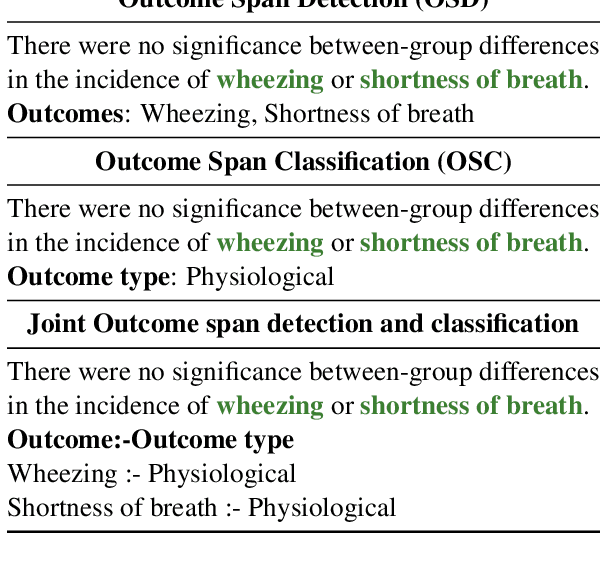
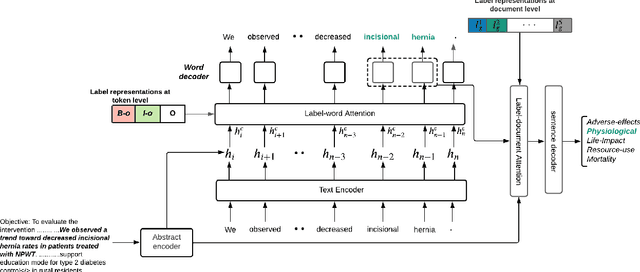
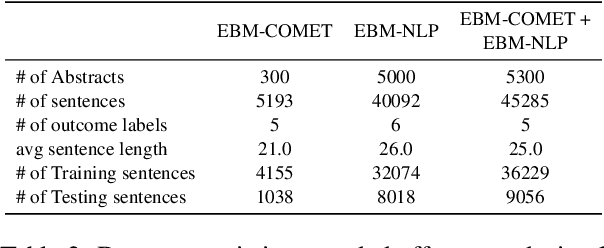
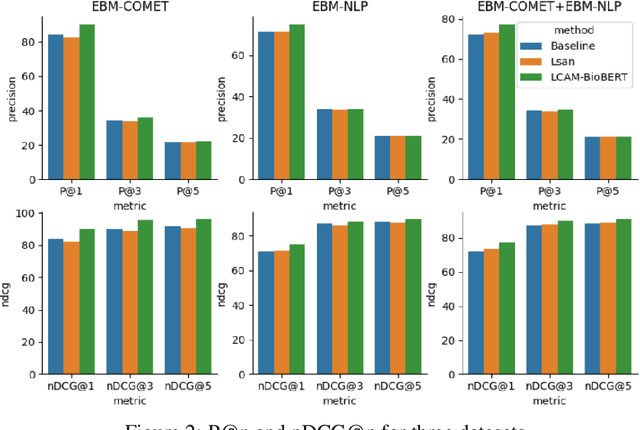
A health outcome is a measurement or an observation used to capture and assess the effect of a treatment. Automatic detection of health outcomes from text would undoubtedly speed up access to evidence necessary in healthcare decision making. Prior work on outcome detection has modelled this task as either (a) a sequence labelling task, where the goal is to detect which text spans describe health outcomes or (b) a classification task, where the goal is to classify a text into a pre-defined set of categories depending on an outcome that is mentioned somewhere in that text. However, this decoupling of span detection and classification is problematic from a modelling perspective and ignores global structural correspondences between sentence-level and word-level information present in a given text. We propose a method that uses both word-level and sentence-level information to simultaneously perform outcome span detection and outcome type classification. In addition to injecting contextual information to hidden vectors, we use label attention to appropriately weight both word-level and sentence-level information. Experimental results on several benchmark datasets for health outcome detection show that our model consistently outperforms decoupled methods, reporting competitive results.