 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFair and Useful Cohort Selection
Sep 04, 2020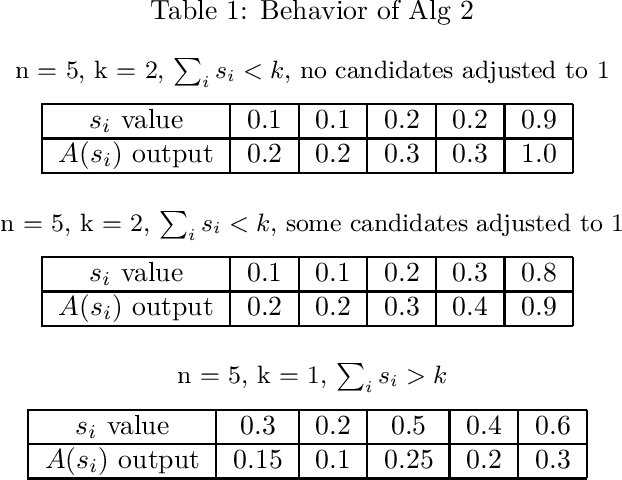

As important decisions about the distribution of society's resources become increasingly automated, it is essential to consider the measurement and enforcement of fairness in these decisions. In this work we build on the results of Dwork and Ilvento ITCS'19, which laid the foundations for the study of fair algorithms under composition. In particular, we study the cohort selection problem, where we wish to use a fair classifier to select $k$ candidates from an arbitrarily ordered set of size $n>k$, while preserving individual fairness and maximizing utility. We define a linear utility function to measure performance relative to the behavior of the original classifier. We develop a fair, utility-optimal $O(n)$-time cohort selection algorithm for the offline setting, and our primary result, a solution to the problem in the streaming setting that keeps no more than $O(k)$ pending candidates at all time.
Factorized Graph Representations for Semi-Supervised Learning from Sparse Data
Mar 05, 2020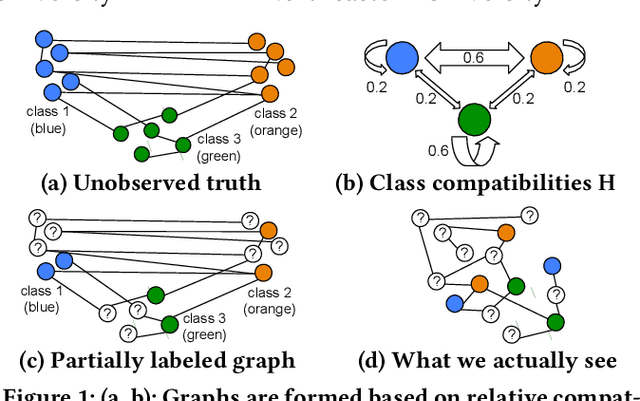
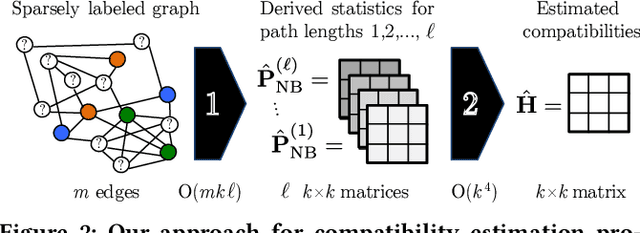
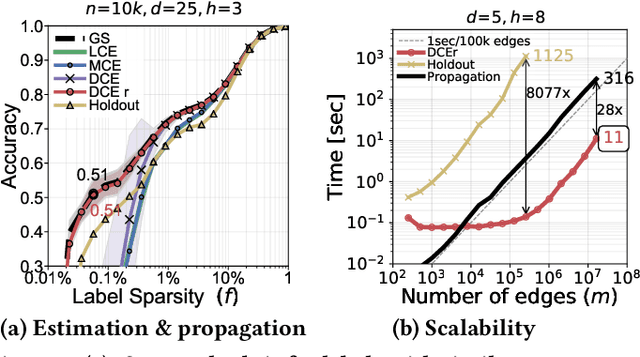
Node classification is an important problem in graph data management. It is commonly solved by various label propagation methods that work iteratively starting from a few labeled seed nodes. For graphs with arbitrary compatibilities between classes, these methods crucially depend on knowing the compatibility matrix that must be provided by either domain experts or heuristics. Can we instead directly estimate the correct compatibilities from a sparsely labeled graph in a principled and scalable way? We answer this question affirmatively and suggest a method called distant compatibility estimation that works even on extremely sparsely labeled graphs (e.g., 1 in 10,000 nodes is labeled) in a fraction of the time it later takes to label the remaining nodes. Our approach first creates multiple factorized graph representations (with size independent of the graph) and then performs estimation on these smaller graph sketches. We define algebraic amplification as the more general idea of leveraging algebraic properties of an algorithm's update equations to amplify sparse signals. We show that our estimator is by orders of magnitude faster than an alternative approach and that the end-to-end classification accuracy is comparable to using gold standard compatibilities. This makes it a cheap preprocessing step for any existing label propagation method and removes the current dependence on heuristics.