 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulticlass Anomaly Detection in GI Endoscopic Images using Optimized Deep One-class Classification in an Imbalanced Dataset
Mar 15, 2021



Wireless Capsule Endoscopy helps physicians examine the gastrointestinal (GI) tract noninvasively, with the cost of generating many images. Many available datasets, such as KID2 and Kvasir, suffer from imbalance issue which make it difficult to train an effective artificial intelligence (AI) system. Moreover, increasing number of classes makes the problem worse. In this study, an ensemble of one-class classifiers is used for detecting anomaly. This method focuses on learning single models using samples from only one class, and ensemble all models for multiclass classification. A total of 1,778 normal, 227 inflammation, 303 vascular diseases, and 44 polyp images have been used from the KID2 dataset. In the first step, deep features are extracted based on an autoencoder architecture from the preprocessed images. Then, these features are oversampled using Synthetic Minority Over-sampling Technique and clustered using Ordering Points to Identify the Clustering Structure. To create one-class classification model, the Support Vector Data Descriptions are trained on each cluster with the help of Ant Colony Optimization, which is also used for tuning clustering parameters for improving F1-score. This process is applied on each classes and ensemble of final models used for multiclass classification. The entire algorithm ran 5 times and obtained F1-score 96.3 +- 0.2% and macro-average F1-score 85.0 +- 0.4%, for anomaly detection and multiclass classification, respectively. The results are compared with GoogleNet, AlexNet, Resnet50, VGG16 and other published algorithms, and demonstrate that the proposed method is a competitive choice for multiclass class anomaly detection in GI images.
Siamese Network Features for Endoscopy Image and Video Localization
Mar 15, 2021



Conventional Endoscopy (CE) and Wireless Capsule Endoscopy (WCE) are known tools for diagnosing gastrointestinal (GI) tract disorders. Localizing frames provide valuable information about the anomaly location and also can help clinicians determine a more appropriate treatment plan. There are many automated algorithms to detect the anomaly. However, very few of the existing works address the issue of localization. In this study, we present a combination of meta-learning and deep learning for localizing both endoscopy images and video. A dataset is collected from 10 different anatomical positions of human GI tract. In the meta-learning section, the system was trained using 78 CE and 27 WCE annotated frames with a modified Siamese Neural Network (SNN) to predict the location of one single image/frame. Then, a postprocessing section using bidirectional long short-term memory is proposed for localizing a sequence of frames. Here, we have employed feature vector, distance and predicted location obtained from a trained SNN. The postprocessing section is trained and tested on 1,028 and 365 seconds of CE and WCE videos using hold-out validation (50%), and achieved F1-score of 86.3% and 83.0%, respectively. In addition, we performed subjective evaluation using nine gastroenterologists. The results show that the computer-aided methods can outperform gastroenterologists assessment of localization. The proposed method is compared with various approaches, such as support vector machine with hand-crafted features, convolutional neural network and the transfer learning-based methods, and showed better results. Therefore, it can be used in frame localization, which can help in video summarization and anomaly detection.
Automatic classification of multiple catheters in neonatal radiographs with deep learning
Nov 14, 2020
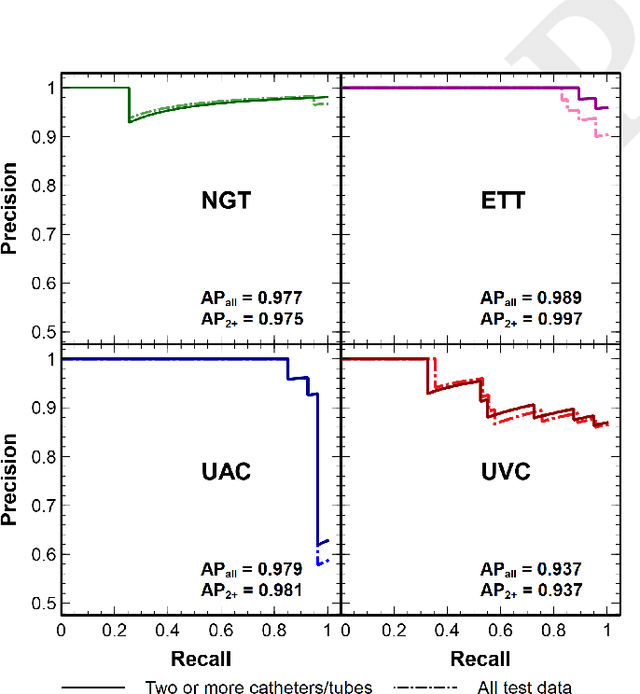
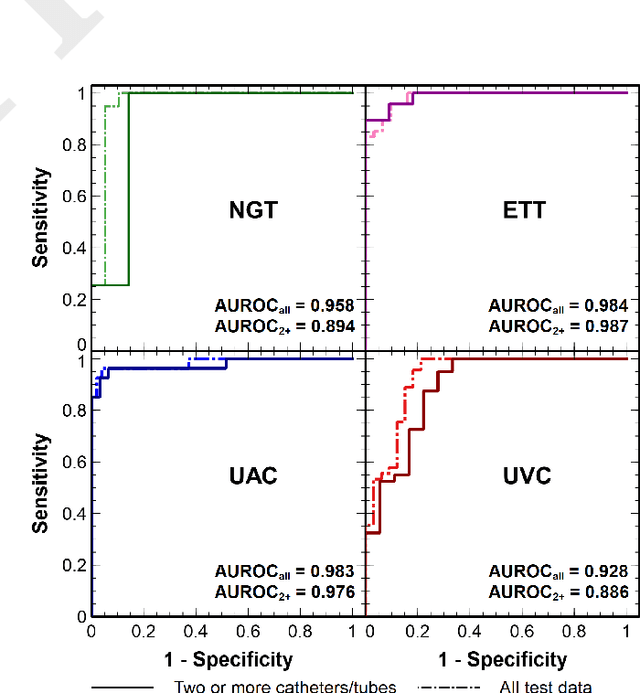
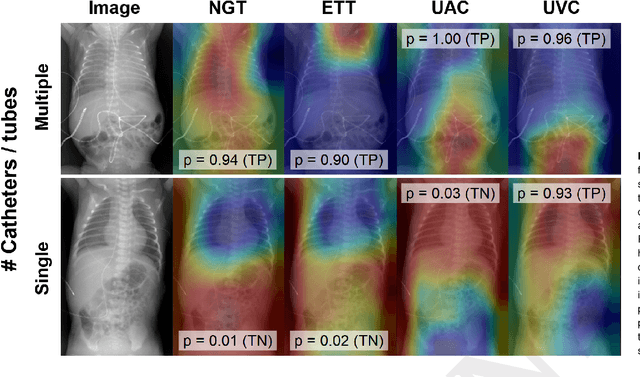
We develop and evaluate a deep learning algorithm to classify multiple catheters on neonatal chest and abdominal radiographs. A convolutional neural network (CNN) was trained using a dataset of 777 neonatal chest and abdominal radiographs, with a split of 81%-9%-10% for training-validation-testing, respectively. We employed ResNet-50 (a CNN), pre-trained on ImageNet. Ground truth labelling was limited to tagging each image to indicate the presence or absence of endotracheal tubes (ETTs), nasogastric tubes (NGTs), and umbilical arterial and venous catheters (UACs, UVCs). The data set included 561 images containing 2 or more catheters, 167 images with only one, and 49 with none. Performance was measured with average precision (AP), calculated from the area under the precision-recall curve. On our test data, the algorithm achieved an overall AP (95% confidence interval) of 0.977 (0.679-0.999) for NGTs, 0.989 (0.751-1.000) for ETTs, 0.979 (0.873-0.997) for UACs, and 0.937 (0.785-0.984) for UVCs. Performance was similar for the set of 58 test images consisting of 2 or more catheters, with an AP of 0.975 (0.255-1.000) for NGTs, 0.997 (0.009-1.000) for ETTs, 0.981 (0.797-0.998) for UACs, and 0.937 (0.689-0.990) for UVCs. Our network thus achieves strong performance in the simultaneous detection of these four catheter types. Radiologists may use such an algorithm as a time-saving mechanism to automate reporting of catheters on radiographs.
Computer-Aided Assessment of Catheters and Tubes on Radiographs: How Good is Artificial Intelligence for Assessment?
Feb 09, 2020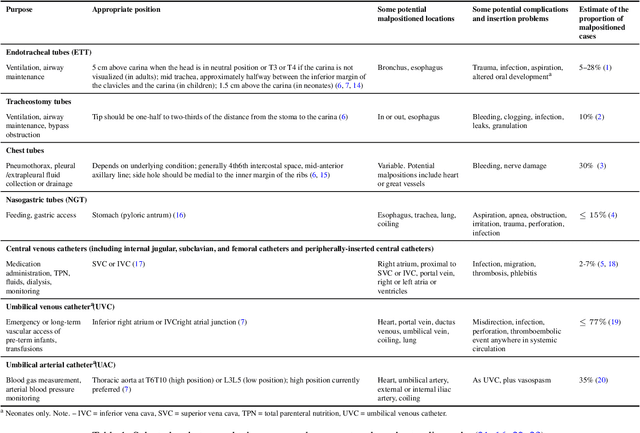
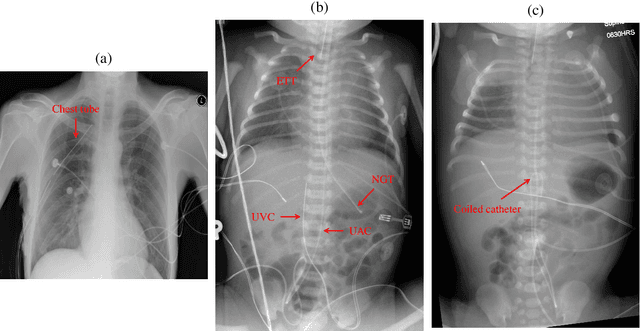

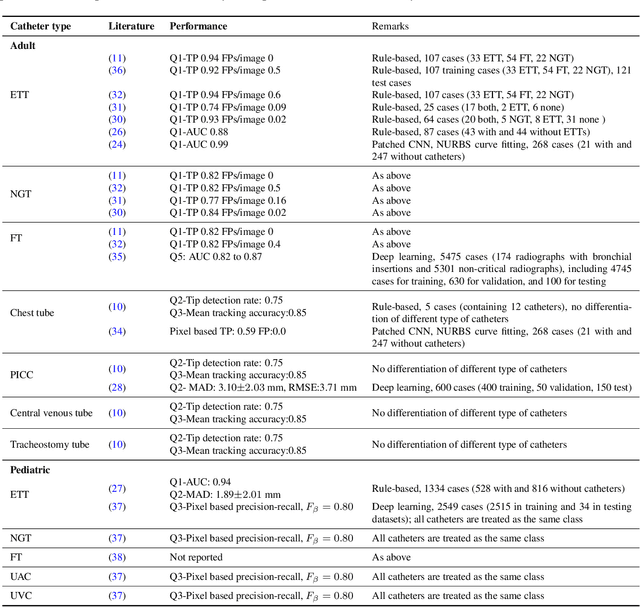
Catheters are the second most common abnormal finding on radiographs. The position of catheters must be assessed on all radiographs, as serious complications can arise if catheters are malpositioned. However, due to the large number of radiographs performed each day, there can be substantial delays between the time a radiograph is performed and when it is interpreted by a radiologist. Computer-aided approaches hold the potential to assist in prioritizing radiographs with potentially malpositioned catheters for interpretation and automatically insert text indicating the placement of catheters in radiology reports, thereby improving radiologists' efficiency. After 50 years of research in computer-aided diagnosis, there is still a paucity of study in this area. With the development of deep learning approaches, the problem of catheter assessment is far more solvable. Therefore, we have performed a review of current algorithms and identified key challenges in building a reliable computer-aided diagnosis system for assessment of catheters on radiographs. This review may serve to further the development of machine learning approaches for this important use case.
Deep Learning for Low-Dose CT Denoising
Feb 25, 2019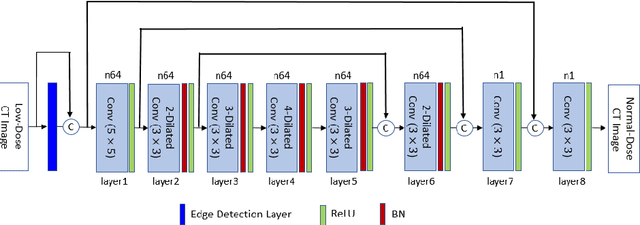
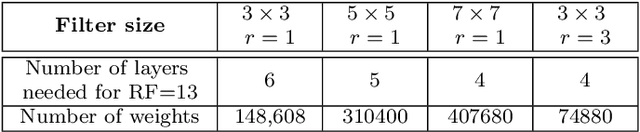
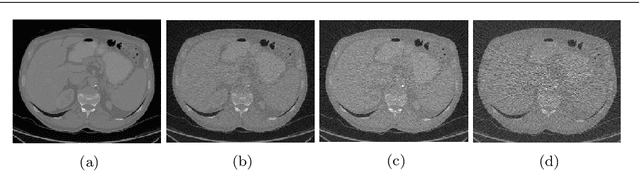
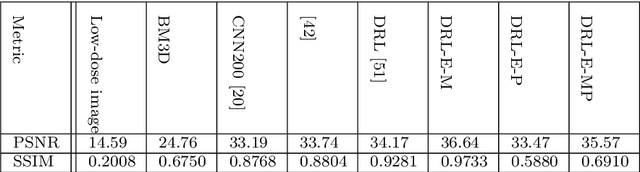
Low-dose CT denoising is a challenging task that has been studied by many researchers. Some studies have used deep neural networks to improve the quality of low-dose CT images and achieved fruitful results. In this paper, we propose a deep neural network that uses dilated convolutions with different dilation rates instead of standard convolution helping to capture more contextual information in fewer layers. Also, we have employed residual learning by creating shortcut connections to transmit image information from the early layers to later ones. To further improve the performance of the network, we have introduced a non-trainable edge detection layer that extracts edges in horizontal, vertical, and diagonal directions. Finally, we demonstrate that optimizing the network by a combination of mean-square error loss and perceptual loss preserves many structural details in the CT image. This objective function does not suffer from over smoothing and blurring effects caused by per-pixel loss and grid-like artifacts resulting from perceptual loss. The experiments show that each modification to the network improves the outcome while only minimally changing the complexity of the network.
Generative Adversarial Network in Medical Imaging: A Review
Sep 19, 2018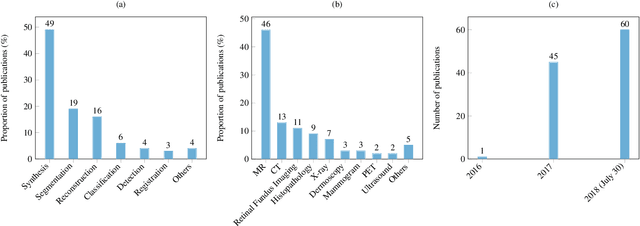
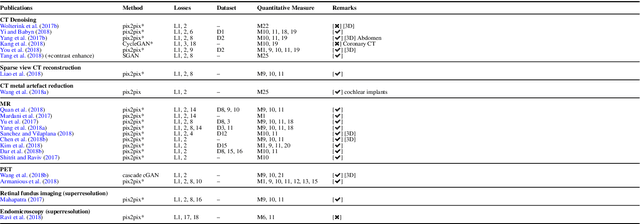
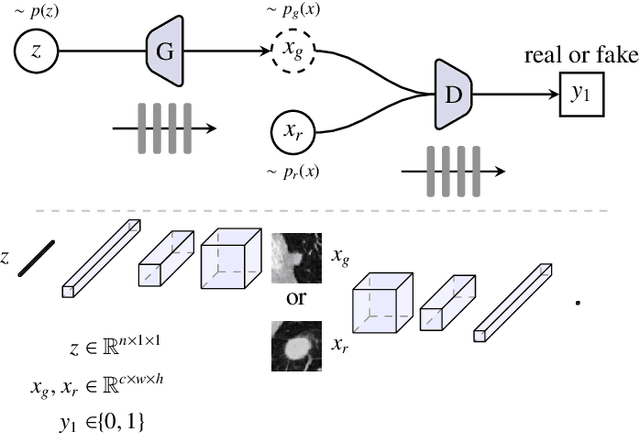

Generative adversarial networks have gained a lot of attention in general computer vision community due to their capability of data generation without explicitly modelling the probability density function and robustness to overfitting. The adversarial loss brought by the discriminator provides a clever way of incorporating unlabeled samples into the training and imposing higher order consistency that is proven to be useful in many cases, such as in domain adaptation, data augmentation, and image-to-image translation. These nice properties have attracted researcher in the medical imaging community and we have seen quick adoptions in many traditional tasks and some novel applications. This trend will continue to grow based on our observation, therefore we conducted a review of the recent advances in medical imaging using the adversarial training scheme in the hope of benefiting researchers that are interested in this technique.
Automatic catheter detection in pediatric X-ray images using a scale-recurrent network and synthetic data
Jun 04, 2018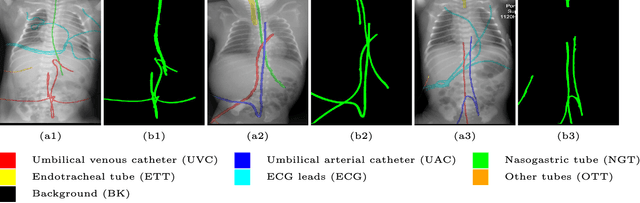
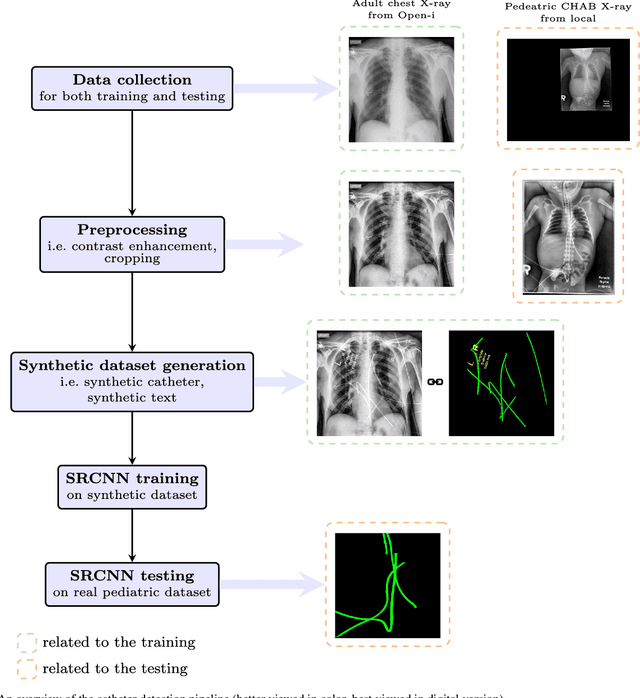
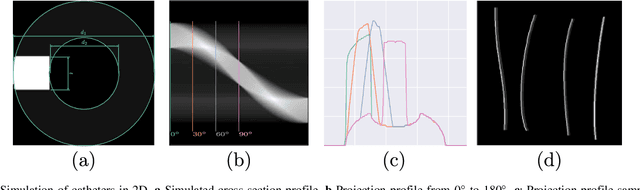
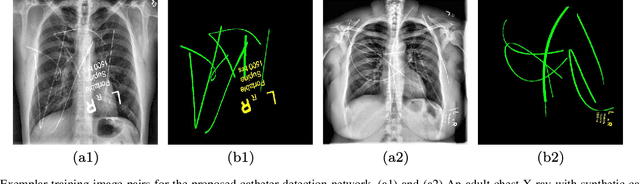
Catheters are commonly inserted life supporting devices. X-ray images are used to assess the position of a catheter immediately after placement as serious complications can arise from malpositioned catheters. Previous computer vision approaches to detect catheters on X-ray images either relied on low-level cues that are not sufficiently robust or only capable of processing a limited number or type of catheters. With the resurgence of deep learning, supervised training approaches are begining to showing promising results. However, dense annotation maps are required, and the work of a human annotator is hard to scale. In this work, we proposed a simple way of synthesizing catheters on X-ray images and a scale recurrent network for catheter detection. By training on adult chest X-rays, the proposed network exhibits promising detection results on pediatric chest/abdomen X-rays in terms of both precision and recall.
Unsupervised and semi-supervised learning with Categorical Generative Adversarial Networks assisted by Wasserstein distance for dermoscopy image Classification
Apr 10, 2018
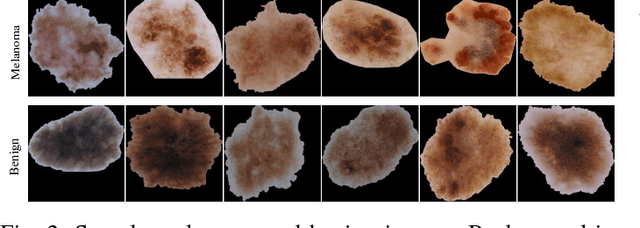


Melanoma is a curable aggressive skin cancer if detected early. Typically, the diagnosis involves initial screening with subsequent biopsy and histopathological examination if necessary. Computer aided diagnosis offers an objective score that is independent of clinical experience and the potential to lower the workload of a dermatologist. In the recent past, success of deep learning algorithms in the field of general computer vision has motivated successful application of supervised deep learning methods in computer aided melanoma recognition. However, large quantities of labeled images are required to make further improvements on the supervised method. A good annotation generally requires clinical and histological confirmation, which requires significant effort. In an attempt to alleviate this constraint, we propose to use categorical generative adversarial network to automatically learn the feature representation of dermoscopy images in an unsupervised and semi-supervised manner. Thorough experiments on ISIC 2016 skin lesion chal- lenge demonstrate that the proposed feature learning method has achieved an average precision score of 0.424 with only 140 labeled images. Moreover, the proposed method is also capable of generating real-world like dermoscopy images.
Sharpness-aware Low dose CT denoising using conditional generative adversarial network
Oct 19, 2017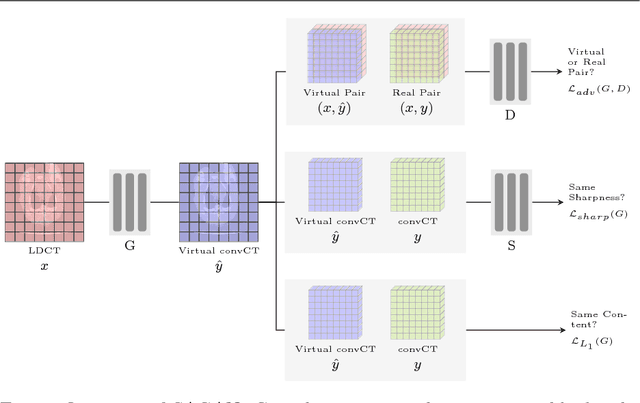
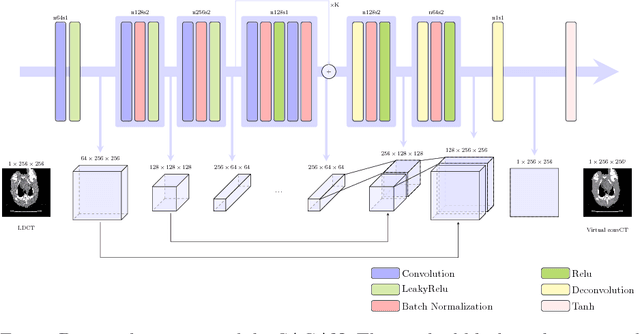
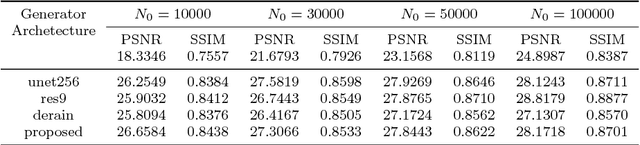
Low Dose Computed Tomography (LDCT) has offered tremendous benefits in radiation restricted applications, but the quantum noise as resulted by the insufficient number of photons could potentially harm the diagnostic performance. Current image-based denoising methods tend to produce a blur effect on the final reconstructed results especially in high noise levels. In this paper, a deep learning based approach was proposed to mitigate this problem. An adversarially trained network and a sharpness detection network were trained to guide the training process. Experiments on both simulated and real dataset shows that the results of the proposed method have very small resolution loss and achieves better performance relative to the-state-of-art methods both quantitatively and visually.