 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance Evaluation and Comparison of a New Regression Algorithm
Jun 15, 2023



In recent years, Machine Learning algorithms, in particular supervised learning techniques, have been shown to be very effective in solving regression problems. We compare the performance of a newly proposed regression algorithm against four conventional machine learning algorithms namely, Decision Trees, Random Forest, k-Nearest Neighbours and XG Boost. The proposed algorithm was presented in detail in a previous paper but detailed comparisons were not included. We do an in-depth comparison, using the Mean Absolute Error (MAE) as the performance metric, on a diverse set of datasets to illustrate the great potential and robustness of the proposed approach. The reader is free to replicate our results since we have provided the source code in a GitHub repository while the datasets are publicly available.
Exploring Supervised Machine Learning for Multi-Phase Identification and Quantification from Powder X-Ray Diffraction Spectra
Nov 16, 2022Powder X-ray diffraction analysis is a critical component of materials characterization methodologies. Discerning characteristic Bragg intensity peaks and assigning them to known crystalline phases is the first qualitative step of evaluating diffraction spectra. Subsequent to phase identification, Rietveld refinement may be employed to extract the abundance of quantitative, material-specific parameters hidden within powder data. These characterization procedures are yet time-consuming and inhibit efficiency in materials science workflows. The ever-increasing popularity and propulsion of data science techniques has provided an obvious solution on the course towards materials analysis automation. Deep learning has become a prime focus for predicting crystallographic parameters and features from X-ray spectra. However, the infeasibility of curating large, well-labelled experimental datasets means that one must resort to a large number of theoretic simulations for powder data augmentation to effectively train deep models. Herein, we are interested in conventional supervised learning algorithms in lieu of deep learning for multi-label crystalline phase identification and quantitative phase analysis for a biomedical application. First, models were trained using very limited experimental data. Further, we incorporated simulated XRD data to assess model generalizability as well as the efficacy of simulation-based training for predictive analysis in a real-world X-ray diffraction application.
An Optimization-Based Supervised Learning Algorithm for PXRD Phase Fraction Estimation
Oct 19, 2022


In powder diffraction data analysis, phase identification is the process of determining the crystalline phases in a sample using its characteristic Bragg peaks. For multiphasic spectra, we must also determine the relative weight fraction of each phase in the sample. Machine Learning algorithms (e.g., Artificial Neural Networks) have been applied to perform such difficult tasks in powder diffraction analysis, but typically require a significant number of training samples for acceptable performance. We have developed an approach that performs well even with a small number of training samples. We apply a fixed-point iteration algorithm on the labelled training samples to estimate monophasic spectra. Then, given an unknown sample spectrum, we again use a fixed-point iteration algorithm to determine the weighted combination of monophase spectra that best approximates the unknown sample spectrum. These weights are the desired phase fractions for the sample. We compare our approach with several traditional Machine Learning algorithms.
A Data Science Approach to Risk Assessment for Automobile Insurance Policies
Sep 06, 2022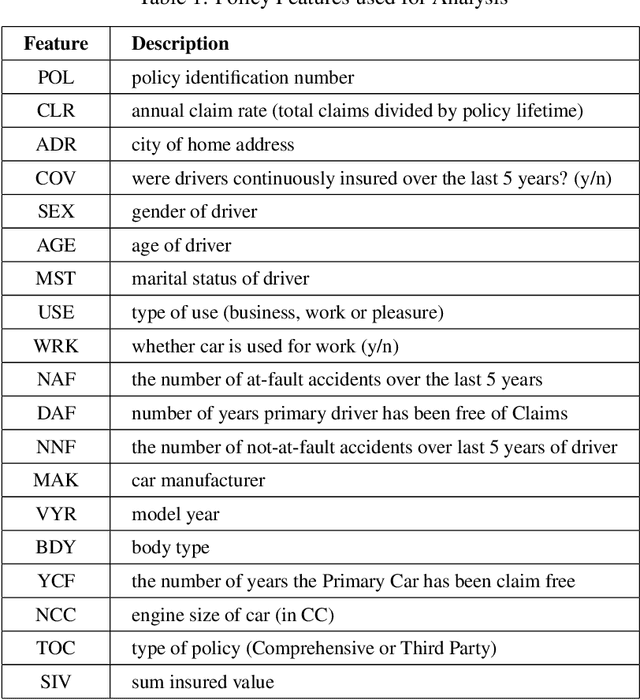



In order to determine a suitable automobile insurance policy premium one needs to take into account three factors, the risk associated with the drivers and cars on the policy, the operational costs associated with management of the policy and the desired profit margin. The premium should then be some function of these three values. We focus on risk assessment using a Data Science approach. Instead of using the traditional frequency and severity metrics we instead predict the total claims that will be made by a new customer using historical data of current and past policies. Given multiple features of the policy (age and gender of drivers, value of car, previous accidents, etc.) one can potentially try to provide personalized insurance policies based specifically on these features as follows. We can compute the average claims made per year of all past and current policies with identical features and then take an average over these claim rates. Unfortunately there may not be sufficient samples to obtain a robust average. We can instead try to include policies that are "similar" to obtain sufficient samples for a robust average. We therefore face a trade-off between personalization (only using closely similar policies) and robustness (extending the domain far enough to capture sufficient samples). This is known as the Bias-Variance Trade-off. We model this problem and determine the optimal trade-off between the two (i.e. the balance that provides the highest prediction accuracy) and apply it to the claim rate prediction problem. We demonstrate our approach using real data.
Bayes Classification using an approximation to the Joint Probability Distribution of the Attributes
May 29, 2022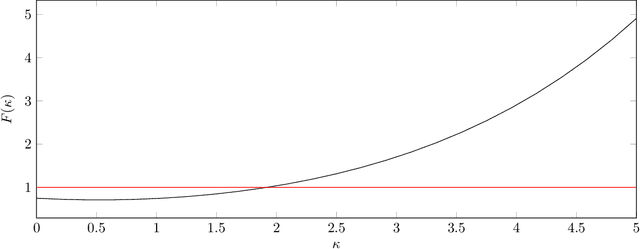
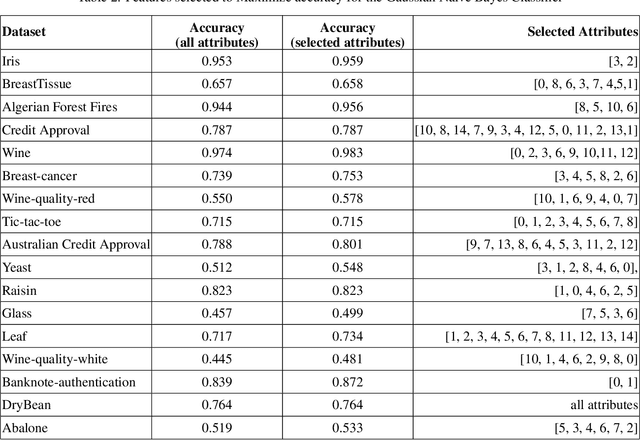
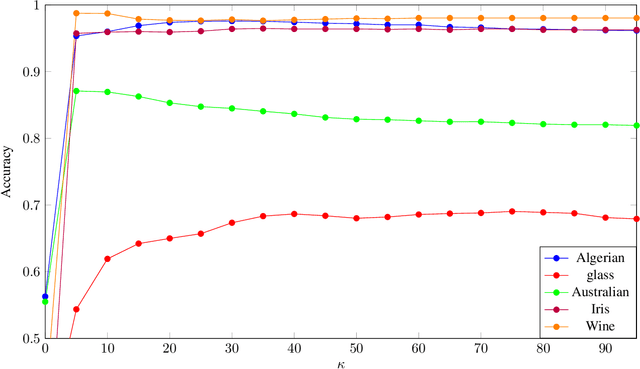
The Naive-Bayes classifier is widely used due to its simplicity, speed and accuracy. However this approach fails when, for at least one attribute value in a test sample, there are no corresponding training samples with that attribute value. This is known as the zero frequency problem and is typically addressed using Laplace Smoothing. However, Laplace Smoothing does not take into account the statistical characteristics of the neighbourhood of the attribute values of the test sample. Gaussian Naive Bayes addresses this but the resulting Gaussian model is formed from global information. We instead propose an approach that estimates conditional probabilities using information in the neighbourhood of the test sample. In this case we no longer need to make the assumption of independence of attribute values and hence consider the joint probability distribution conditioned on the given class which means our approach (unlike the Gaussian and Laplace approaches) takes into consideration dependencies among the attribute values. We illustrate the performance of the proposed approach on a wide range of datasets taken from the University of California at Irvine (UCI) Machine Learning Repository. We also include results for the $k$-NN classifier and demonstrate that the proposed approach is simple, robust and outperforms standard approaches.
Improving Power Generation Efficiency using Deep Neural Networks
Jun 16, 2016



Recently there has been significant research on power generation, distribution and transmission efficiency especially in the case of renewable resources. The main objective is reduction of energy losses and this requires improvements on data acquisition and analysis. In this paper we address these concerns by using consumers' electrical smart meter readings to estimate network loading and this information can then be used for better capacity planning. We compare Deep Neural Network (DNN) methods with traditional methods for load forecasting. Our results indicate that DNN methods outperform most traditional methods. This comes at the cost of additional computational complexity but this can be addressed with the use of cloud resources. We also illustrate how these results can be used to better support dynamic pricing.