 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Data Science Approach to Risk Assessment for Automobile Insurance Policies
Paper and Code
Sep 06, 2022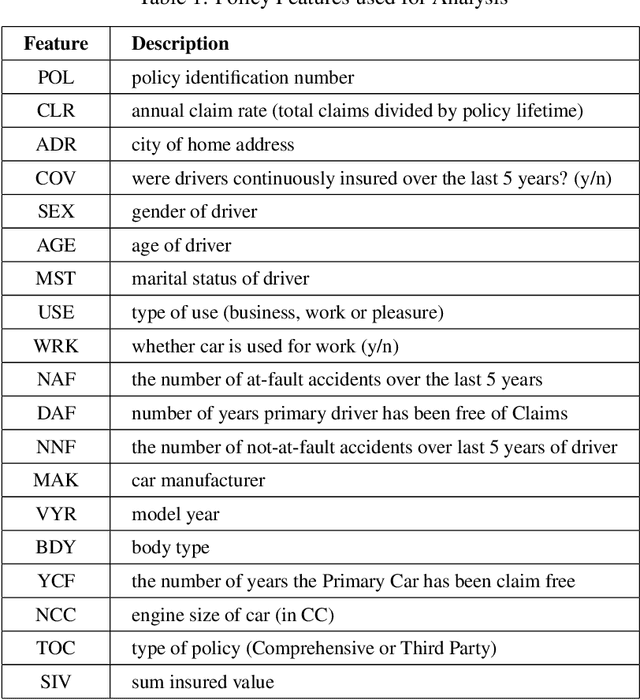



In order to determine a suitable automobile insurance policy premium one needs to take into account three factors, the risk associated with the drivers and cars on the policy, the operational costs associated with management of the policy and the desired profit margin. The premium should then be some function of these three values. We focus on risk assessment using a Data Science approach. Instead of using the traditional frequency and severity metrics we instead predict the total claims that will be made by a new customer using historical data of current and past policies. Given multiple features of the policy (age and gender of drivers, value of car, previous accidents, etc.) one can potentially try to provide personalized insurance policies based specifically on these features as follows. We can compute the average claims made per year of all past and current policies with identical features and then take an average over these claim rates. Unfortunately there may not be sufficient samples to obtain a robust average. We can instead try to include policies that are "similar" to obtain sufficient samples for a robust average. We therefore face a trade-off between personalization (only using closely similar policies) and robustness (extending the domain far enough to capture sufficient samples). This is known as the Bias-Variance Trade-off. We model this problem and determine the optimal trade-off between the two (i.e. the balance that provides the highest prediction accuracy) and apply it to the claim rate prediction problem. We demonstrate our approach using real data.