 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Corpus for Detecting High-Context Medical Conditions in Intensive Care Patient Notes Focusing on Frequently Readmitted Patients
Mar 06, 2020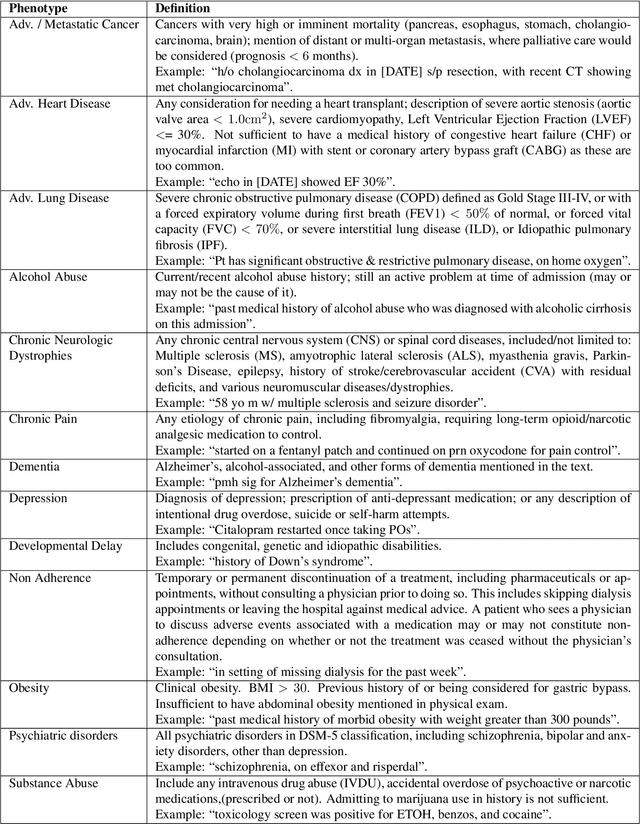
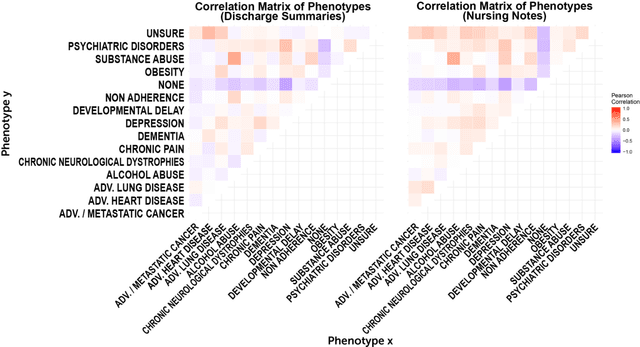
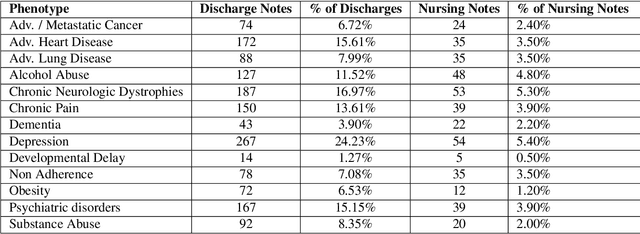
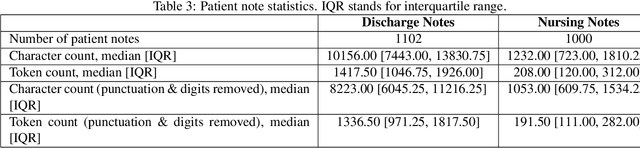
A crucial step within secondary analysis of electronic health records (EHRs) is to identify the patient cohort under investigation. While EHRs contain medical billing codes that aim to represent the conditions and treatments patients may have, much of the information is only present in the patient notes. Therefore, it is critical to develop robust algorithms to infer patients' conditions and treatments from their written notes. In this paper, we introduce a dataset for patient phenotyping, a task that is defined as the identification of whether a patient has a given medical condition (also referred to as clinical indication or phenotype) based on their patient note. Nursing Progress Notes and Discharge Summaries from the Intensive Care Unit of a large tertiary care hospital were manually annotated for the presence of several high-context phenotypes relevant to treatment and risk of re-hospitalization. This dataset contains 1102 Discharge Summaries and 1000 Nursing Progress Notes. Each Discharge Summary and Progress Note has been annotated by at least two expert human annotators (one clinical researcher and one resident physician). Annotated phenotypes include treatment non-adherence, chronic pain, advanced/metastatic cancer, as well as 10 other phenotypes. This dataset can be utilized for academic and industrial research in medicine and computer science, particularly within the field of medical natural language processing.
Comparing Rule-Based and Deep Learning Models for Patient Phenotyping
Mar 25, 2017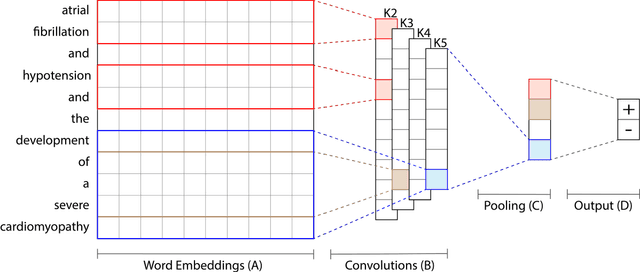



Objective: We investigate whether deep learning techniques for natural language processing (NLP) can be used efficiently for patient phenotyping. Patient phenotyping is a classification task for determining whether a patient has a medical condition, and is a crucial part of secondary analysis of healthcare data. We assess the performance of deep learning algorithms and compare them with classical NLP approaches. Materials and Methods: We compare convolutional neural networks (CNNs), n-gram models, and approaches based on cTAKES that extract pre-defined medical concepts from clinical notes and use them to predict patient phenotypes. The performance is tested on 10 different phenotyping tasks using 1,610 discharge summaries extracted from the MIMIC-III database. Results: CNNs outperform other phenotyping algorithms in all 10 tasks. The average F1-score of our model is 76 (PPV of 83, and sensitivity of 71) with our model having an F1-score up to 37 points higher than alternative approaches. We additionally assess the interpretability of our model by presenting a method that extracts the most salient phrases for a particular prediction. Conclusion: We show that NLP methods based on deep learning improve the performance of patient phenotyping. Our CNN-based algorithm automatically learns the phrases associated with each patient phenotype. As such, it reduces the annotation complexity for clinical domain experts, who are normally required to develop task-specific annotation rules and identify relevant phrases. Our method performs well in terms of both performance and interpretability, which indicates that deep learning is an effective approach to patient phenotyping based on clinicians' notes.