 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Corpus for Detecting High-Context Medical Conditions in Intensive Care Patient Notes Focusing on Frequently Readmitted Patients
Mar 06, 2020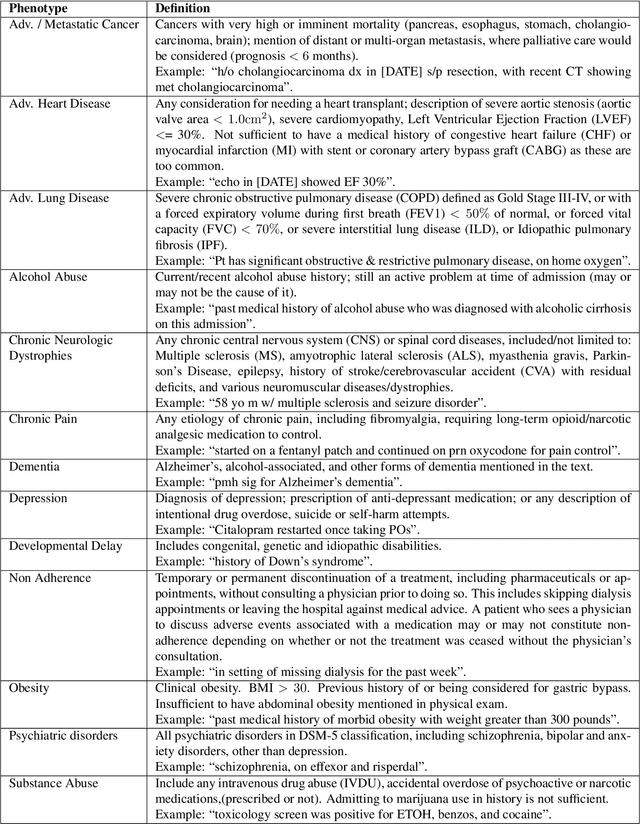
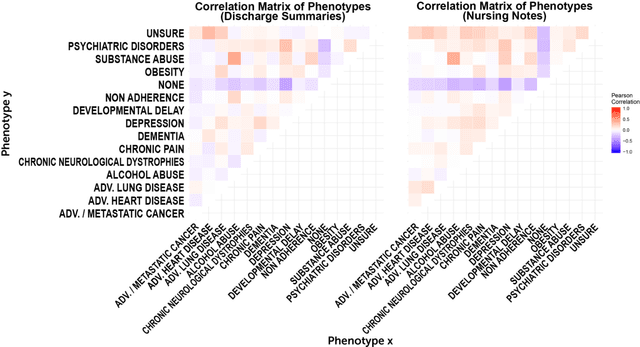
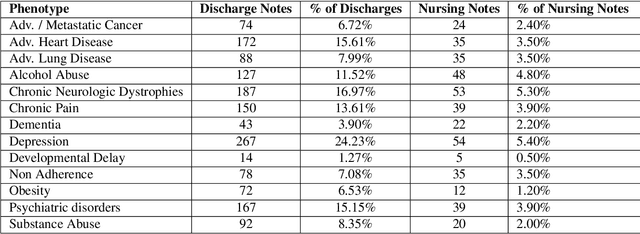
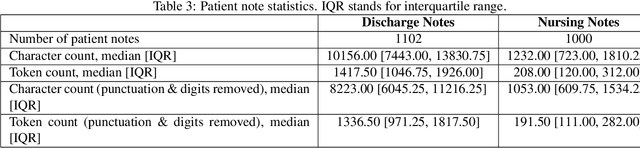
A crucial step within secondary analysis of electronic health records (EHRs) is to identify the patient cohort under investigation. While EHRs contain medical billing codes that aim to represent the conditions and treatments patients may have, much of the information is only present in the patient notes. Therefore, it is critical to develop robust algorithms to infer patients' conditions and treatments from their written notes. In this paper, we introduce a dataset for patient phenotyping, a task that is defined as the identification of whether a patient has a given medical condition (also referred to as clinical indication or phenotype) based on their patient note. Nursing Progress Notes and Discharge Summaries from the Intensive Care Unit of a large tertiary care hospital were manually annotated for the presence of several high-context phenotypes relevant to treatment and risk of re-hospitalization. This dataset contains 1102 Discharge Summaries and 1000 Nursing Progress Notes. Each Discharge Summary and Progress Note has been annotated by at least two expert human annotators (one clinical researcher and one resident physician). Annotated phenotypes include treatment non-adherence, chronic pain, advanced/metastatic cancer, as well as 10 other phenotypes. This dataset can be utilized for academic and industrial research in medicine and computer science, particularly within the field of medical natural language processing.