 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatch Selection for Melanoma Classification
Jun 27, 2022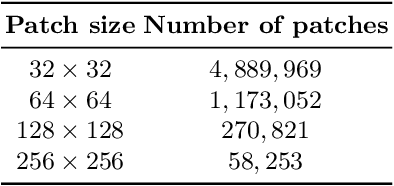
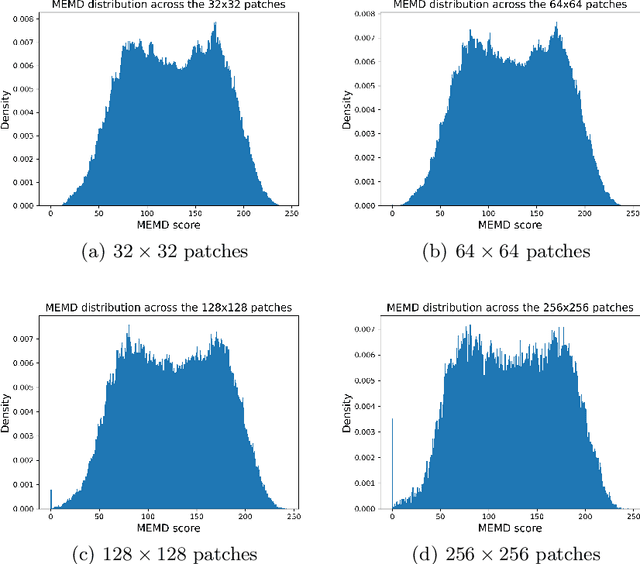
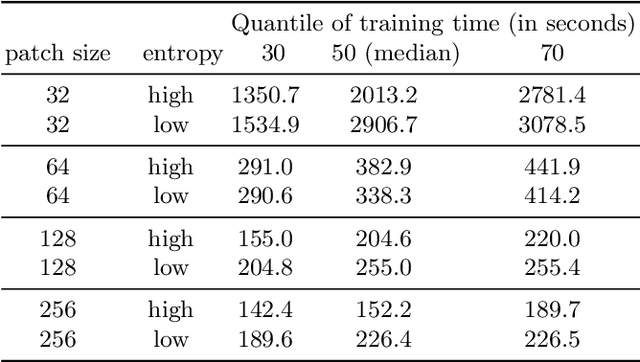

In medical image processing, the most important information is often located on small parts of the image. Patch-based approaches aim at using only the most relevant parts of the image. Finding ways to automatically select the patches is a challenge. In this paper, we investigate two criteria to choose patches: entropy and a spectral similarity criterion. We perform experiments at different levels of patch size. We train a Convolutional Neural Network on the subsets of patches and analyze the training time. We find that, in addition to requiring less preprocessing time, the classifiers trained on the datasets of patches selected based on entropy converge faster than on those selected based on the spectral similarity criterion and, furthermore, lead to higher accuracy. Moreover, patches of high entropy lead to faster convergence and better accuracy than patches of low entropy.
Automatic Detection of Sexist Statements Commonly Used at the Workplace
Jul 08, 2020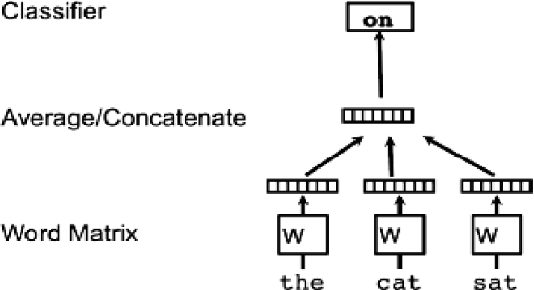
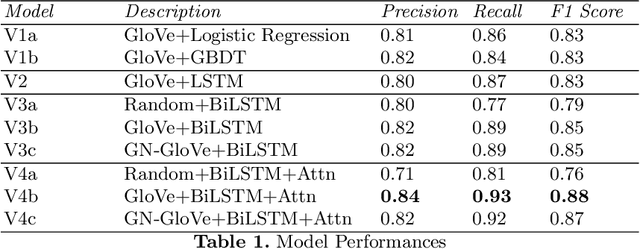
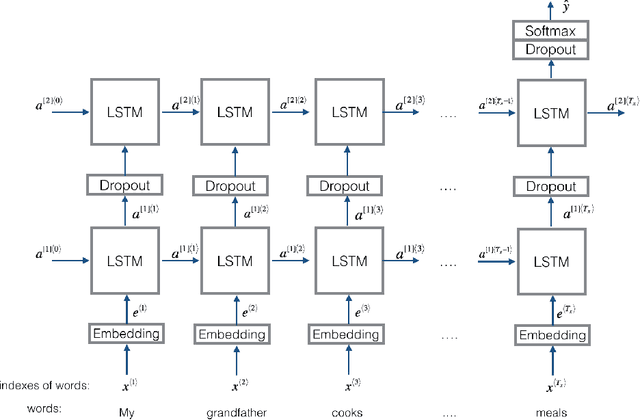
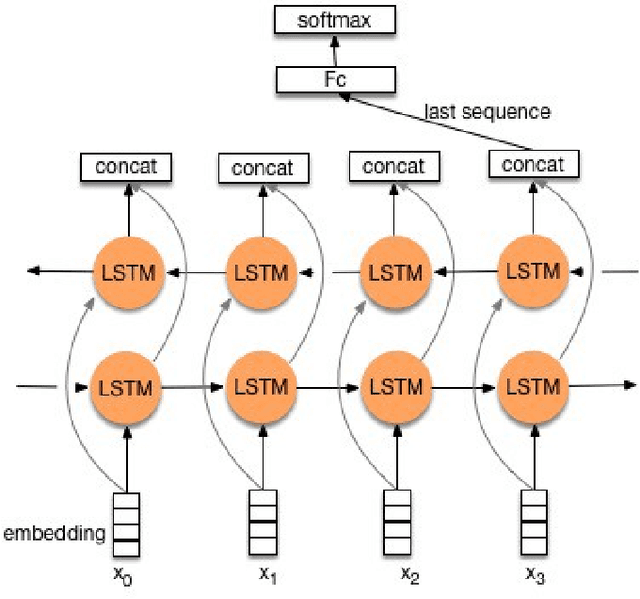
Detecting hate speech in the workplace is a unique classification task, as the underlying social context implies a subtler version of conventional hate speech. Applications regarding a state-of the-art workplace sexism detection model include aids for Human Resources departments, AI chatbots and sentiment analysis. Most existing hate speech detection methods, although robust and accurate, focus on hate speech found on social media, specifically Twitter. The context of social media is much more anonymous than the workplace, therefore it tends to lend itself to more aggressive and "hostile" versions of sexism. Therefore, datasets with large amounts of "hostile" sexism have a slightly easier detection task since "hostile" sexist statements can hinge on a couple words that, regardless of context, tip the model off that a statement is sexist. In this paper we present a dataset of sexist statements that are more likely to be said in the workplace as well as a deep learning model that can achieve state-of-the art results. Previous research has created state-of-the-art models to distinguish "hostile" and "benevolent" sexism based simply on aggregated Twitter data. Our deep learning methods, initialized with GloVe or random word embeddings, use LSTMs with attention mechanisms to outperform those models on a more diverse, filtered dataset that is more targeted towards workplace sexism, leading to an F1 score of 0.88.