 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisrupting Resilient Criminal Networks through Data Analysis: The case of Sicilian Mafia
Mar 10, 2020

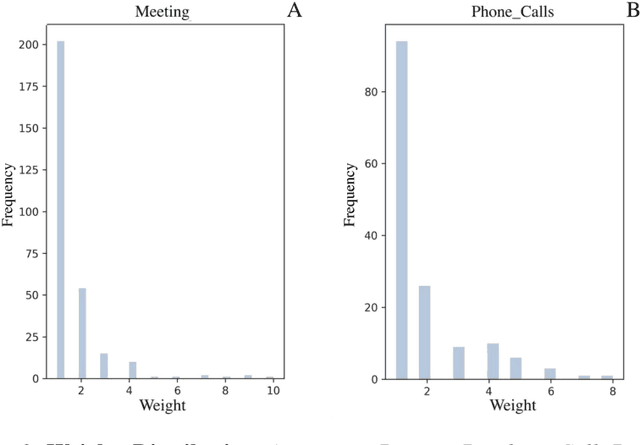
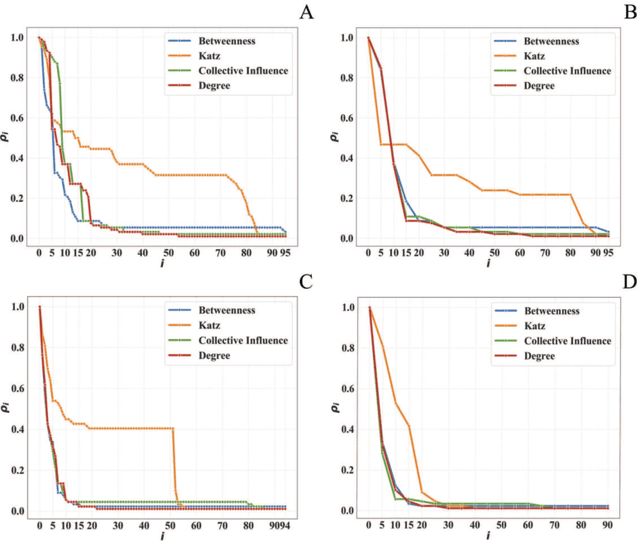
Compared to other types of social networks, criminal networks present hard challenges, due to their strong resilience to disruption, which poses severe hurdles to law-enforcement agencies. Herein, we borrow methods and tools from Social Network Analysis to (i) unveil the structure of Sicilian Mafia gangs, based on two real-world datasets, and (ii) gain insights as to how to efficiently disrupt them. Mafia networks have peculiar features, due to the links distribution and strength, which makes them very different from other social networks, and extremely robust to exogenous perturbations. Analysts are also faced with the difficulty in collecting reliable datasets that accurately describe the gangs' internal structure and their relationships with the external world, which is why earlier studies are largely qualitative, elusive and incomplete. An added value of our work is the generation of two real-world datasets, based on raw data derived from juridical acts, relating to a Mafia organization that operated in Sicily during the first decade of 2000s. We created two different networks, capturing phone calls and physical meetings, respectively. Our network disruption analysis simulated different intervention procedures: (i) arresting one criminal at a time (sequential node removal); and (ii) police raids (node block removal). We measured the effectiveness of each approach through a number of network centrality metrics. We found Betweeness Centrality to be the most effective metric, showing how, by neutralizing only the 5% of the affiliates, network connectivity dropped by 70%. We also identified that, due the peculiar type of interactions in criminal networks (namely, the distribution of the interactions frequency) no significant differences exist between weighted and unweighted network analysis. Our work has significant practical applications for tackling criminal and terrorist networks.
XML Matchers: approaches and challenges
Jul 10, 2014

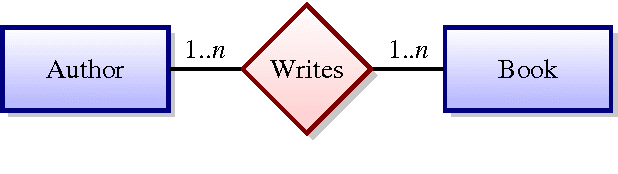
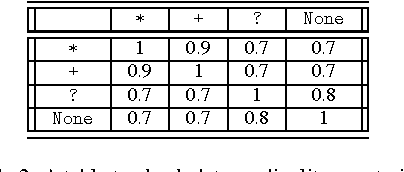
Schema Matching, i.e. the process of discovering semantic correspondences between concepts adopted in different data source schemas, has been a key topic in Database and Artificial Intelligence research areas for many years. In the past, it was largely investigated especially for classical database models (e.g., E/R schemas, relational databases, etc.). However, in the latest years, the widespread adoption of XML in the most disparate application fields pushed a growing number of researchers to design XML-specific Schema Matching approaches, called XML Matchers, aiming at finding semantic matchings between concepts defined in DTDs and XSDs. XML Matchers do not just take well-known techniques originally designed for other data models and apply them on DTDs/XSDs, but they exploit specific XML features (e.g., the hierarchical structure of a DTD/XSD) to improve the performance of the Schema Matching process. The design of XML Matchers is currently a well-established research area. The main goal of this paper is to provide a detailed description and classification of XML Matchers. We first describe to what extent the specificities of DTDs/XSDs impact on the Schema Matching task. Then we introduce a template, called XML Matcher Template, that describes the main components of an XML Matcher, their role and behavior. We illustrate how each of these components has been implemented in some popular XML Matchers. We consider our XML Matcher Template as the baseline for objectively comparing approaches that, at first glance, might appear as unrelated. The introduction of this template can be useful in the design of future XML Matchers. Finally, we analyze commercial tools implementing XML Matchers and introduce two challenging issues strictly related to this topic, namely XML source clustering and uncertainty management in XML Matchers.
* 34 pages, 8 tables, 7 figures